Elasticsearch7.8.0
很完整的课程参考文档:https://blog.csdn.net/SeniorShen/article/details/111591122,这里面的内容可以参考一下,总结的还是不错
简介
互联网的数据一般分为图片、文章、视频、网站信息,一般根据数据的格式会将数据分成三个大类,结构化数据、非结构化数据、半结构化数据
结构化数据使用特定的结构如二维表结构来组织和管理数据,一般这些数据间都有关系,使用关系型数据库Mysql、Oracle,通过sql语句来查询数据并使用索引对查询进行优化,这种方式方便管理和查询,但是扩展结构很难;
非结构化数据无法使用二维表结构来表现数据,如服务器日志、通信记录、工作文档、报表、视频、图片等维度广、数据量大,数据存储和查询的成本很大,这种数据一般存在存入nosql数据库中,如MongoDB、Redis、DataBase,以key-value结构保存,通过key查询对应数据,相对来说比较快,这种数据一般需要专业的人员和大量的统计模型来进行处理;
半结构化数据是将数据和结构混合在一起,没有明显的区分,比如xml、html,这种文档就是半结构化数据,这种数据一般也是保存在MongoDB、Redis、DataBase中,缺点是查询其中的数据内容不是很方便;ES用户解决实时准确地查询任何来源、任何格式的数据【同时包含结构化数据和非结构化数据】,然后实时地对数据进行搜索、分析和可视化的问题
EalsticSearch解决的就是如何准确查询结构化数据和非结构化数据的问题,开源的Elasticsearch是目前全文搜索引擎的首选。它可以快速地存储、搜索和分析海量数据。 维基百科、Stack Overflow、Github都采用它。 Elastic的底层是开源库Lucene【Lucene是使用java开发的】,Elastic是Lucene的封装,提供了REST API的操作接口,开箱即用。全文搜索又叫全站搜索,用户可以根据热门词汇查询整个网站中的热门文章并以列表的形式展现结果
ES请求和响应体的数据都是json串的格式,数据发送和返回都是json格式,json全称JavaScript Object Notation,表示一种特殊标记的JavaScript对象;json格式特别适合将对象用字符串进行网络传递;而一个对象无法使用网络传递,只能通过序列化后传递然后在客户端反序列化为对象,比较麻烦;json字符串就是网络传递数据的字符串符合json格式的字符串
官方文档:[Elasticsearch Guide 8.13] | Elastic
ElasticSearch将Apache的Lucene封装到REST API级别,封装度非常高,不像MySQL一样需要引入配置驱动包,编写CRUD代码
HTTP API
以下使用Postman测试,实际生产中可以内嵌到网页中来发起请求提交和查询数据
http://localhost:9200【Get】测试ES的HTTP协议的RestFul端口
http://127.0.0.1:9200/shopping【PUT】ES创建索引,等同于创建数据库
幂等性,重复发起报错
http://127.0.0.1:9200/_cat/indices?v【GET】查看ES中的所有索引
http://127.0.0.1:9200/shopping【GET】查看单个索引的内容简介【不包含数据】
http://127.0.0.1:9200/shopping【DELETE】删除ES中单个索引
http://127.0.0.1:9200/shopping/_doc【POST】【请求体提交JSON格式数据】索引已经创建好了,接下来我们来创建文档,并添加数据,数据格式为json,这种方式生成的文档数据的标识是随机唯一标识,不指定主键ID的文档数据添加不能为PUT方式,会报错
http://127.0.0.1:9200/shopping/_doc/1【POST】【请求体提交JSON格式数据】,指定自定义唯一标识主键ID的文档数据添加,明确数据主键的请求方式可以为PUT,两种请求方式都可以,区别不明确主键的方式
http://127.0.0.1:9200/shopping/_doc/1【GET】根据文档的唯一主键标识让ES服务器返回对应的文档数据,文档数据在
_source属性中,传入什么内容,响应_source属性内容就是什么内容
http://127.0.0.1:9200/shopping/_search【GET】查看单个索引下的所有文档数据,单个查看的响应结果以json数组的方式赋值给hits.hits属性
http://127.0.0.1:9200/shopping/_doc/1【POST】【请求体提交JSON格式数据】全量修改,带唯一标识主键ID,会将原来数据完全覆盖
请求体json
xxxxxxxxxx{"title":"华为手机","category":"华为","images":"http://www.gulixueyuan.com/hw.jpg","price":1999.00}
http://127.0.0.1:9200/shopping/_update/1【POST】【请求体提交JSON格式数据】局部修改,在json对象的doc属性中传递需要修改的数据
请求体json
xxxxxxxxxx{"doc": {"title":"小米手机","category":"小米"}}
http://127.0.0.1:9200/shopping/_doc/1【DELETE 】删除索引下对应主键的文档数据,删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)
http://127.0.0.1:9200/shopping/_search?q=category:小米【GET】查询索引shopping下的文档数据中包含属性category为小米的所有文档数据,响应也是响应所有满足条件的数据显示在hits.hits中
URL带参数形式查询,不善者容易搞攻击,或参数值出现中文可能乱码。避免这些情况可使用带JSON请求体请求进行查询
http://127.0.0.1:9200/shopping/_search【GET】woc,GET请求可以带请求体
查询文档中满足属性category的值为小米的请求体JSON
xxxxxxxxxx{"query":{"match":{"category":"小米"}}}查询对应索引下的所有文档数据的请求体JSON
xxxxxxxxxx{"query":{"match_all":{}}}查询索引下所有结果文档数据并只显示文档数据指定属性的JSON
"_source":["title"]表示只显示_source属性下的title属性xxxxxxxxxx{"query":{"match_all":{}},"_source":["title"]}查询索引下所有内容并分页显示的请求体JSON
from是当前页的第一条数据的条数,满足
(页数-1)*每页展示条数,比如下面的例子就是(2-1)*2,表示展示第二页数据,每页展示两条数据,响应索引下总的数据条数和当前页需要展示的数据xxxxxxxxxx{"query":{"match_all":{}},"from":2,"size":2}同一个索引下的查询结果根据某个属性进行排序的请求体JSON
sort.price.order表示使用文档数据的price属性来进行排序xxxxxxxxxx{"query":{"match_all":{}},"sort":{"price":{"order":"desc"}}}
http://127.0.0.1:9200/shopping/_search【GET】【请求体JSON数据】对一个索引下的文档数据多条件查询
多条件同时满足【交集】使用must的请求体JSON
must相当于数据库的
&&,查询文档数据中同时包含"category":"小米"和"price":3999.00的文档数据xxxxxxxxxx{"query":{"bool":{"must":[{"match":{"category":"小米"}},{"match":{"price":3999.00}}]}}}满足多条件中的一个【并集】使用should的请求体JSON
should相当于数据库的
||,查询文档数据中包含"category":"小米"或者"category":"华为"的文档数据xxxxxxxxxx{"query":{"bool":{"should":[{"match":{"category":"小米"}},{"match":{"category":"华为"}}]}}}满足范围查询使用filter的请求体json
filter.range表示范围查询,price表示根据price属性进行范围查询,
"gt":2000表示大于2000;即对查询结果中文档数据的price属性大于2000的数据进行展示xxxxxxxxxx{"query":{"bool":{"should":[{"match":{"category":"小米"}},{"match":{"category":"华为"}}],"filter":{"range":{"price":{"gt":2000}}}}}}
http://127.0.0.1:9200/shopping/_search【GET】【请求体:JSON数据】全文检索的请求体JSON
像搜索引擎一样,查询匹配内容输入“小华”,返回结果带回品牌有“小米”和"华为",原因是ES对match条件中的数据匹配时会将查询请求需要匹配的属性值拆分成一个单独的字符,对每个字符都进行单独匹配再汇总,
"category" : "小米"只会查询到category属性下能匹配上小的文档数据和能匹配上米的文档数据,取并集进行输出;"category" : "小华"会查询匹配文档数据中能匹配小字的文档数据和能匹配上华字的文档数据并求并集返回json数据
xxxxxxxxxx{"query":{"match":{"category" : "小华"}}}
完全匹配
会精确地去匹配输出的查询条件,此时对
match_phrase输入的属性值会去精确匹配文档数据,比如匹配"category" : "小华"就会精确地找文档中的category属性含有小华的文档数据json数据
下面的匹配条件就会返回文档数据总数为0,如果是match匹配会返回category属性含有小米和华为的文档数据的并集
xxxxxxxxxx{"query":{"match_phrase":{"category" : "小华"}}}
高亮查询
用
hightlight属性指定查询数据的某个属性的属性值高亮显示的json请求体数据,就是在对应的内容两边添加html标签,每个文字都会添加这个标签,为什么不一起添加该标签?以下就是查询shopping索引下的category属性值匹配"为"的文档数据
json数据
xxxxxxxxxx{"query":{"match_phrase":{"category" : "为"}},"highlight":{"fields":{"category":{}//<----高亮category这字段}}}
http://127.0.0.1:9200/shopping/_search【GET】【请求体:json数据】聚合查询
允许使用者对es文档进行统计分析,类似与关系型数据库中的group by,当然还有很多其他的聚合,例如取最大值max、平均值avg等等,就是根据指定的属性值分组,对每一组的文档数量进行计数
带回索引下满足条件的完整文档内容和统计数据的请求体JSON
响应数据中仍然是
hits.hits中是所有的文档数据,在aggregations.buckets中是对应的分组数据,分组只显示对应的分组属性值和相应的数量请求体json中的"terms"的含义是根据内部指定字段对数据进行分组,内部写分组依据的字段
xxxxxxxxxx{"aggs":{//聚合操作"price_group":{//名称,随意起名"terms":{//分组"field":"price"//分组字段}}}}不带回文档数据只带回统计数据的请求体JSON
加了size属性的属性值为0,响应的
hits.hits就是空串xxxxxxxxxx{"aggs":{"price_group":{"terms":{"field":"price"}}},"size":0}对指定属性值求平均值的请求体
xxxxxxxxxx{"aggs":{"price_avg":{//名称,随意起名"avg":{//求平均"field":"price"}}},"size":0}
http://localhost:1004/_cluster/health【GET】集群中某个节点和整个集群的状态检查响应内容
注意,更改了ES集群中某个节点的配置文件【端口号】,需要将ES文件的数据目录删掉,否则查询集群健康状态会报错error并响应状态码503
"status": "green",表示集群状态正常"number_of_nodes": 1,表示当前集群节点数量为1"number_of_data_nodes": 1,表示当前数据节点数量为1
xxxxxxxxxx{"cluster_name": "my-application","status": "green","timed_out": false,"number_of_nodes": 1,"number_of_data_nodes": 1,"active_primary_shards": 0,"active_shards": 0,"relocating_shards": 0,"initializing_shards": 0,"unassigned_shards": 0,"delayed_unassigned_shards": 0,"number_of_pending_tasks": 0,"number_of_in_flight_fetch": 0,"task_max_waiting_in_queue_millis": 0,"active_shards_percent_as_number": 100.0}
Java API
环境搭建
创建maven项目并配置pom.xml
xxxxxxxxxx<dependencies><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.8.0</version></dependency><!-- elasticsearch 的客户端,elasticsearch中获取客户端的方法已经过时了,官方说在8.x版本会将其移除,这里使用elasticsearch-rest-high-level-client中获取客户端的工具类 --><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.8.0</version></dependency><!-- elasticsearch 依赖 2.x 的 log4j --><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.9.9</version></dependency><!-- junit 单元测试 --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency></dependencies>对应文档数据的实体类
x/*** @author Earl* @version 1.0.0* @描述 准备vo来封装数据模型* @创建日期 2024/01/23* @since 1.0.0*/public class User {private String name;private String sex;private Integer age;public String getName() {return name;}public void setName(String name) {this.name = name;}public String getSex() {return sex;}public void setSex(String sex) {this.sex = sex;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}}
创建操作ES的客户端
xxxxxxxxxxpublic class ESTest01_Client {/*** @param args* @描述 创建ES客户端的JAVA-API并测试链接,需要ES服务器开启,不报错就是对象创建成功即链接成功* @author Earl* @version 1.0.0* @创建日期 2024/01/23* @since 1.0.0*/public static void main(String[] args) throws Exception {// 创建ES客户端//TransportClient创建ES客户端的工具已经过时,并且在8.x的版本会正式删除,这里不使用TransportClient,// 使用elasticsearch-rest-high-level-client中的RestHighLevelClient//创建ES客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 关闭ES客户端esClient.close();}}创建索引
xxxxxxxxxxpublic class ESTest02_Index_Create {/*** @param args* @描述 通过javaAPI在ES服务器上创建索引* @author Earl* @version 1.0.0* @创建日期 2024/01/23* @since 1.0.0*/public static void main(String[] args) throws Exception {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 创建索引CreateIndexRequest request = new CreateIndexRequest("user");CreateIndexResponse createIndexResponse =esClient.indices().create(request, RequestOptions.DEFAULT);// 响应状态,返回响应的内容中的acknowledged属性,成功创建返回trueboolean acknowledged = createIndexResponse.isAcknowledged();System.out.println("索引操作 :" + acknowledged);esClient.close();}}查询索引
xxxxxxxxxxpublic class ESTest03_Index_Search {/*** @param args* @描述 获取索引信息,不包含索引下的文档内容* @author Earl* @version 1.0.0* @创建日期 2024/01/23* @since 1.0.0*/public static void main(String[] args) throws Exception {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 查询索引GetIndexRequest request = new GetIndexRequest("user");GetIndexResponse getIndexResponse =esClient.indices().get(request, RequestOptions.DEFAULT);// 响应内容,和postman发起的请求是一样的,后面三个对应响应内容的三个属性System.out.println(getIndexResponse.getAliases());System.out.println(getIndexResponse.getMappings());System.out.println(getIndexResponse.getSettings());esClient.close();}}删除索引
xxxxxxxxxxpublic class ESTest04_Index_Delete {/*** @param args* @描述 通过索引名删除索引* @author Earl* @version 1.0.0* @创建日期 2024/01/23* @since 1.0.0*/public static void main(String[] args) throws Exception {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 查询索引DeleteIndexRequest request = new DeleteIndexRequest("user");AcknowledgedResponse response = esClient.indices().delete(request, RequestOptions.DEFAULT);// 响应状态System.out.println(response.isAcknowledged());System.out.println(response);esClient.close();}}新增文档
xxxxxxxxxxpublic class ESTest05_Doc_Insert {/*** @param args* @描述 向索引中插入文档数据* @author Earl* @version 1.0.0* @创建日期 2024/01/23* @since 1.0.0*/public static void main(String[] args) throws Exception {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 插入数据IndexRequest request = new IndexRequest();request.index("user").id("1001");User user = new User();user.setName("zhangsan");user.setAge(30);user.setSex("男");// 向ES插入数据,必须将数据转换位JSON格式,这里将对象转成json用的是jackson-databind的ObjectMapper的writeValueAsString方法ObjectMapper mapper = new ObjectMapper();String userJson = mapper.writeValueAsString(user);//声明数据内容的类型是JSONrequest.source(userJson, XContentType.JSON);IndexResponse response = esClient.index(request, RequestOptions.DEFAULT);System.out.println(response.getResult());esClient.close();}}修改文档
xxxxxxxxxxpublic class ESTest06_Doc_Update {public static void main(String[] args) throws Exception {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 修改数据UpdateRequest request = new UpdateRequest();request.index("user").id("1001");request.doc(XContentType.JSON, "sex", "女");UpdateResponse response = esClient.update(request, RequestOptions.DEFAULT);System.out.println(response.getResult());esClient.close();}}查询文档
xxxxxxxxxxpublic class ESTest07_Doc_Get {public static void main(String[] args) throws Exception {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 查询数据GetRequest request = new GetRequest();request.index("user").id("1001");GetResponse response = esClient.get(request, RequestOptions.DEFAULT);System.out.println(response.getSourceAsString());esClient.close();}}删除文档
xxxxxxxxxxpublic class ESTest08_Doc_Delete {public static void main(String[] args) throws Exception {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));DeleteRequest request = new DeleteRequest();request.index("user").id("1001");DeleteResponse response = esClient.delete(request, RequestOptions.DEFAULT);System.out.println(response.toString());esClient.close();}}批量新增文档
xxxxxxxxxxpublic class ESTest09_Doc_Insert_Batch {public static void main(String[] args) throws Exception {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 批量插入数据BulkRequest request = new BulkRequest();request.add(new IndexRequest().index("user").id("1001").source(XContentType.JSON, "name", "zhangsan", "age",30,"sex","男"));request.add(new IndexRequest().index("user").id("1002").source(XContentType.JSON, "name", "lisi", "age",30,"sex","女"));request.add(new IndexRequest().index("user").id("1003").source(XContentType.JSON, "name", "wangwu", "age",40,"sex","男"));request.add(new IndexRequest().index("user").id("1004").source(XContentType.JSON, "name", "wangwu1", "age",40,"sex","女"));request.add(new IndexRequest().index("user").id("1005").source(XContentType.JSON, "name", "wangwu2", "age",50,"sex","男"));request.add(new IndexRequest().index("user").id("1006").source(XContentType.JSON, "name", "wangwu3", "age",50,"sex","男"));request.add(new IndexRequest().index("user").id("1007").source(XContentType.JSON, "name", "wangwu44", "age",60,"sex","男"));request.add(new IndexRequest().index("user").id("1008").source(XContentType.JSON, "name", "wangwu555", "age",60,"sex","男"));request.add(new IndexRequest().index("user").id("1009").source(XContentType.JSON, "name", "wangwu66666", "age",60,"sex","男"));request.add(new IndexRequest().index("user").id("1010").source(XContentType.JSON, "name", "赵六", "age",60,"sex","男"));request.add(new IndexRequest().index("user").id("1011").source(XContentType.JSON, "name", "赵七", "age",60,"sex","男"));request.add(new IndexRequest().index("user").id("1012").source(XContentType.JSON, "name", "赵八", "age",60,"sex","男"));request.add(new IndexRequest().index("user").id("1013").source(XContentType.JSON, "name", "小六", "age",60,"sex","男"));request.add(new IndexRequest().index("user").id("1014").source(XContentType.JSON, "name", "小七", "age",60,"sex","男"));request.add(new IndexRequest().index("user").id("1015").source(XContentType.JSON, "name", "小八", "age",60,"sex","男"));request.add(new IndexRequest().index("user").id("1016").source(XContentType.JSON, "name", "wang1wu", "age",60,"sex","男"));request.add(new IndexRequest().index("user").id("1017").source(XContentType.JSON, "name", "wa1ng2wu", "age",60,"sex","男"));BulkResponse response = esClient.bulk(request, RequestOptions.DEFAULT);System.out.println(response.getTook());System.out.println(response.getItems());esClient.close();}}批量删除文档
xxxxxxxxxxpublic class ESTest10_Doc_Delete_Batch {public static void main(String[] args) throws Exception {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 批量删除数据BulkRequest request = new BulkRequest();request.add(new DeleteRequest().index("user").id("1001"));request.add(new DeleteRequest().index("user").id("1002"));request.add(new DeleteRequest().index("user").id("1003"));request.add(new DeleteRequest().index("user").id("1004"));request.add(new DeleteRequest().index("user").id("1005"));request.add(new DeleteRequest().index("user").id("1006"));request.add(new DeleteRequest().index("user").id("1007"));request.add(new DeleteRequest().index("user").id("1008"));request.add(new DeleteRequest().index("user").id("1009"));BulkResponse response = esClient.bulk(request, RequestOptions.DEFAULT);System.out.println(response.getTook());System.out.println(response.getItems());esClient.close();}}高级查询API
xxxxxxxxxxpublic class ESTest11_Doc_Query {public static void main(String[] args) throws Exception {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 1. 查询索引中全部的数据/*SearchRequest request = new SearchRequest();request.indices("user");//构造查询条件,这是查询一个索引下的所有request.source(new SearchSourceBuilder().query(QueryBuilders.matchAllQuery()));SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}*/// 2. 条件查询 : termQuery,按字段精确匹配查询/*SearchRequest request = new SearchRequest();request.indices("user");request.source(new SearchSourceBuilder().query(QueryBuilders.termQuery("age", 30)));SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}*/// 3. 分页查询/*SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());// from中是(当前页码-1)*每页显示数据条数builder.from(2);builder.size(2);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}*/// 4. 查询排序/*SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());//对查询结果按照年龄进行升序builder.sort("age", SortOrder.DESC);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}*/// 5. 过滤字段/*SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());String[] excludes = {"age","sex"};String[] includes = {};//includes和excludes是包含和排除哪些字段,是两个数组builder.fetchSource(includes, excludes);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}*/// 6. 组合查询/*SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();//boolQueryBuilder.must(QueryBuilders.matchQuery("age", 30));//boolQueryBuilder.must(QueryBuilders.matchQuery("sex", "男"));//还可以用不是什么mustNot//boolQueryBuilder.mustNot(QueryBuilders.matchQuery("sex", "男"));//boolQueryBuilder.should(QueryBuilders.matchQuery("age", 30));//boolQueryBuilder.should(QueryBuilders.matchQuery("age", 40));//注意分词查询只能是中文的情况,英文输入QueryBuilders.matchQuery("name", "wang")查询到的数据是0,must是同时满足;should是满足其中一个boolQueryBuilder.should(QueryBuilders.matchQuery("name", "小赵"));//中文小开头的和赵开头的都能查到,貌似只有中文能分词builder.query(boolQueryBuilder);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}*/// 7. 范围查询/*SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();//对某个字段获取查询范围对象RangeQueryBuilder rangeQuery = QueryBuilders.rangeQuery("age");//大于30,小于50rangeQuery.gte(30);rangeQuery.lt(50);builder.query(rangeQuery);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}*/// 8. 模糊查询/*SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();//匹配name字段为字符串wangwu,fuzziness(Fuzziness.TWO))是允许有两个字符不匹配,就是整个name属性能去掉任意两个以下字符匹配上wangwu就能被查询出来//builder.query(QueryBuilders.fuzzyQuery("name", "wangwu").fuzziness(Fuzziness.TWO));//中文也是可以的builder.query(QueryBuilders.fuzzyQuery("name", "六").fuzziness(Fuzziness.TWO));request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}*/// 9. 高亮查询/*SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("name.keyword", "小六");//TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("name.keyword", "zhangsan");HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.preTags("<font color='red'>");highlightBuilder.postTags("</font>");//对查询结果的name字段做高亮显示highlightBuilder.field("name");builder.highlighter(highlightBuilder);builder.query(termsQueryBuilder);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());System.out.println(response);for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());//highlight标签在hits.hits属性中,是其子属性,同时response重写了toString方法,可以直接显示其中的属性值和结构//注意这里查匹配到对应字段为中文,需要使用 QueryBuilders.termsQuery("name.keyword", "小六");才能查询出来,否则查不来对应字// 段是中文的,且就算查出来,hits.hits中也没有高亮属性System.out.println(hit.getHighlightFields());}*/// 10. 聚合查询/*SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();//maxAge会显示在响应的数据中作为对age字段求最大值后的属性名AggregationBuilder aggregationBuilder = AggregationBuilders.max("maxAge").field("age");builder.aggregation(aggregationBuilder);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());System.out.println(response);for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}*/// 11. 分组查询SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();AggregationBuilder aggregationBuilder = AggregationBuilders.terms("ageGroup").field("age");builder.aggregation(aggregationBuilder);request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println(hits.getTotalHits());System.out.println(response.getTook());System.out.println(response);for ( SearchHit hit : hits ) {System.out.println(hit.getSourceAsString());}esClient.close();}}查询指定索引下的全部文档
xxxxxxxxxxpublic class ESTest12_Doc_Search {public static void main(String[] args) throws Exception {RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 1. 查询索引的所有数据SearchRequest request = new SearchRequest();request.indices("user");// 构造查询条件SearchSourceBuilder builder = new SearchSourceBuilder();builder.query(QueryBuilders.matchAllQuery());request.source(builder);SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println(response.getTook());System.out.println(hits.getTotalHits());Iterator<SearchHit> iterator = hits.iterator();while (iterator.hasNext()) {SearchHit hit = iterator.next();System.out.println(hit.getSourceAsString());}esClient.close();}}
RESTFUL简介
RESTful的REST是Representational State Transfer的开头,表示请求资源状态转换
简介
缩写:REST【不是"rest"这个单词】
外文名:Representational State Transfer,简称REST,
Resource:资源,即数据(这是网络的核心)
Representational:某种表现形式,比如用JSON,XML,JPEG等
State Transfer:状态变化。通过HTTP的动词(get查询、post新增、put修改、delete删除)实现
中文名:表现层状态转移
提出时间:2000年
属性:一种软件架构风格【以Web为平台的。web服务的架构风格,前后端接口时候用到】,是一种组织Web服务的架构,不是一种技术也不是一种标准,作为一种架构,其提出了一系列架构级约束
Rest架构的五条约束
一个系统满足了上面所列出的五条约束,那么该系统就被称为是RESTful的
使用客户/服务器(b/s、 c/s)模型。客户和服务器之间通过一个统一的接口来互相通讯。
层次化的系统。在一个REST系统中,客户端并不会固定地与一个服务器打交道。
无状态。在一个REST系统中,服务端并不会保存有关客户的任何状态。也就是说,客户端自身负责用户状态的维持,并在每次发送请求时都需要提供足够的信息。
可缓存。REST系统需要能够恰当地缓存请求,以尽量减少服务端和客户端之间的信息传输,以提高性能。
统一的接口。一个REST系统需要使用一个统一的接口来完成子系统之间以及服务与用户之间的交互。这使得REST系统中的各个子系统可以独自完成演化。【无论什么样的资源都应该使用相同的相同的接口对资源进行访问,使用HTTP协议提供的标准请求方式对资源进行操作;即对同一资源的访问都使用相同的URI,URI管理资源的定位;使用不同的方法来对同一个资源进行不同的操作,幂等性,后续无论多少次GET、PUT、DELETE、HEAD请求都是幂等性的,无论后续发起多少次相同的请求都不会对数据产生更多的影响,但是POST请求就不是幂等性的了】
Rest架构的优点
URI:统一资源路径,作为资源的唯一标识
适合做前后端分离项目
前端拿到数据只负责展示和渲染,不对数据做任何处理。后端处理数据并以JSON格式传输出去,定义这样一套统一的接口,在web,ios,android三端都可以用相同的接口,RESTFUL让后端接口实现天然的跨平台【因为不需要写三次代码,一次代码可以公用给三端;另外,修改代码只要修改一次,三端都同步访问新代码,不需要修改三次代码】
集群配置
windows环境
清空根目录下的data文件目录和logs目录下的所有文件
因为以前可能使用过该软件,导致有数据
直接删掉整个data文件夹
保留logs目录,清空logs目录下的所有的文件
在
config/ealsticsearch.yml对集群环境的第一个节点进行配置默认配置全是注释,集群环境下需要对以下指定选项进行配置
集群名称
cluster.name: my-application,多个EalsticSearch节点的集群名称必须相同当前节点的名字
node.name: node-1,同一个EalsticSearch集群每个节点的名字不能重复主机名称
network.host: localhost,当前节点所在的主机的IPHttp端口号
http.port: 1001TCP通信监听端口号
transport.tcp.port: 9301指定当前节点是master节点和数据节点
xxxxxxxxxxnode.mastertruenode.datatrue跨域配置
xxxxxxxxxxhttp.cors.enabledtruehttp.cors.allow-origin"*"双击
/bin/elasticsearch.bat启动该节点启动以后能看到以下控制台日志说明启动成功,不成功可能是端口号占用,端口排查和杀掉进程查看【工具目录下的windows指南】
xxxxxxxxxx[2024-04-13T17:59:19,809][INFO ][o.e.n.Node ] [node-1] node name [node-1], node ID [7aDVXWxuRMirgLOTBBgUPw], cluster name [my-application]使用PostMan发送请求
http://localhost:1004/_cluster/health【GET】检查集群中某个节点和整个集群的状态请求任意一台节点的HTTP端口都行,都会显示当前节点的状态信息和集群信息
响应内容
注意,更改了ES集群中某个节点的配置文件【端口号】,需要将ES文件的数据目录删掉,否则查询集群健康状态会报错error并响应状态码503
"status": "green",表示集群状态正常"number_of_nodes": 1,表示当前集群节点数量为1"number_of_data_nodes": 1,表示当前数据节点数量为1
xxxxxxxxxx{"cluster_name": "my-application","status": "green","timed_out": false,"number_of_nodes": 1,"number_of_data_nodes": 1,"active_primary_shards": 0,"active_shards": 0,"relocating_shards": 0,"initializing_shards": 0,"unassigned_shards": 0,"delayed_unassigned_shards": 0,"number_of_pending_tasks": 0,"number_of_in_flight_fetch": 0,"task_max_waiting_in_queue_millis": 0,"active_shards_percent_as_number": 100.0}
配置集群其他节点
将第一个节点的整个ES拷贝一份新的,将data目录删掉,logs目录下的所有文件全部删掉
更改
config/elasticsearch.yml中的节点名称、Http端口号、TCP通信监听端口号在后续节点
config/elasticsearch.yml添加以下配置ES的单个节点不知道其他节点的具体位置,需要使用下列配置对ES进行告知,这是ES中查找节点的模块;第一台机器【还是master机器不用加?】不需要添加该配置【注意此时第二个节点的配置中仍然还是
node.master: true】,该配置是让其他节点去找第一台机器discovery.seed_hosts: ["localhost:9301"]是去查找第一台节点的集群内部通信端口xxxxxxxxxxdiscovery.seed_hosts"localhost:9301"discovery.zen.fd.ping_timeout1mdiscovery.zen.fd.ping_retries5同样的方式启动节点2,用PostMan发送请求
http://localhost:1004/_cluster/health【GET】访问集群状态注意一旦更改过第一个节点的配置【端口】,其他节点的data文件夹就需要删掉,否则其他节点启动也会报错,节点新建的时候拷贝的副本也需要删掉data目录,
第三台机器启动的时候既可以查找第一台机器的9301端口,也可以查找第二台机器的9302端口,所以节点发现的主机端口是一个数组,由已经运行的可供当前节点发现集群的任意一台节点端口组成【?疑问,为什么不将所有节点的该属性设置为其他节点】
常见问题
以上配置在一次启动以后如果发生中途master节点变更以后第二次就启动不了的情况,使用请求
http://127.0.0.1:1004/_cluster/health【GET】报错如下:删除data目录和日志也启动不了且报错相同,这里有可能是节点状态发生变更后发生的错误,很大原因可能是删除了data目录导致启动以后找不到master节点,或者也可能添加了第三方的分析器;但是无论如何,添加下面的配置
cluster.initial_master_nodes: node-1不会出问题,而且再次启动集群不需要删除data目录,master节点状态也时正常的xxxxxxxxxx{"error": {"root_cause": [{"type": "master_not_discovered_exception","reason": null}],"type": "master_not_discovered_exception","reason": null},"status": 503}需要在每个节点配置文件添加以下配置重启所有ES节点即可
这种方式不会影响master节点重选宕机节点重启以后的master节点,仍然遵循下次master节点故障后再重选的原则
xxxxxxxxxxcluster.initial_master_nodesnode-1
Linux环境
安装ElasticSearch
安装步骤
从地址
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-8-0选中LINUX_X86_64 sha下载指定版本的Linux版本的ES压缩包elasticsearch-7.8.0-linux-x86_64.tar.gz并上传至Linux系统在上传目录使用命令
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz解压缩压缩包,解压后的名字较长,使用命令mv elasticsearch-7.8.0 es-7.8.0将ES的名字修改为es-7.8.0使用root用户创建新用户来使用es
出于安全问题,ES不允许root用户直接运行,需要在root用户中创建新的用户
使用命令
useradd es为linux系统创建es用户使用命令
passwd es在弹窗界面为es用户设置密码如果用户创建错误可以使用命令
userdel -r es删除用户es使用命令
chown -R es:es /opt/elasticsearch/es-7.8.0设置es用户为es解压文件的所有者
修改根目录下的配置文件
/config/elasticsearch.yml,添加以下配置xxxxxxxxxx# 加入如下配置# 设置集群名称为elasticsearch,默认就叫elasticsearchcluster.nameelasticsearch# 设置节点名称为node-1node.namenode-1# 不用管,按样子配置,这个没讲network.host0.0.0.0#配置HTTP端口号为9200http.port9200# 将当前节点作为master节点,中括号中的名称要和当前节点的名称保持一致cluster.initial_master_nodes"node-1"修改Linux系统配置文件
ES生成的数据和文件比较多,生成文件时使用系统默认配置可能会出一些问题,需要对系统的配置进行修改
使用
vim /etc/security/limits.conf修改文件/etc/security/limits.conf,在文件末尾添加每个进程可以打开的文件数的限制的以下配置xxxxxxxxxx# 在文件末尾中增加下面内容# 每个进程可以打开的文件数的限制es soft nofile 65536es hard nofile 65536使用命令
vim /etc/security/limits.d/20-nproc.conf修改系统配置文件,在文件末尾添加以下配置xxxxxxxxxx# 在文件末尾中增加下面内容# 每个进程可以打开的文件数的限制es soft nofile 65536es hard nofile 65536# 操作系统级别对每个用户创建的进程数的限制* hard nproc 4096# 注: * 带表 Linux 所有用户名称使用命令
vim /etc/sysctl.conf在文件末尾追加配置一个进程可以拥有的虚拟内存的数量xxxxxxxxxx# 在文件中增加下面内容# 一个进程可以拥有的 VMA(虚拟内存区域)的数量,默认值为 65536vm.max_map_count=655360使用命令
sysctl -p重新加载系统配置
启动ES
不能直接进入es根目录使用命令
bin/elasticsearch运行程序,会直接报错,因为不允许使用root用户运行程序,要使用命令su es将当前系统用户切换成es【或者自定义用户】再使用命令bin/elasticsearch来运行程序,此时如果之前没有设置chown -R es:es /opt/elasticsearch/es-7.8.0用户权限,此时启动创建文件会出现问题
安装成功测试
正常启动的效果和windows是一样的,只要出现控制台日志
[2024-04-13T17:59:19,809][INFO ][o.e.n.Node] [node-1] node name [node-1], node ID [7aDVXWxuRMirgLOTBBgUPw], cluster name [my-application]没有报错就是正常启动了,更准确的测试是像服务器发送请求http://192.168.200.136:9200/_cluster/health查询节点状态并响应如下内容注意这一步发送请求需要关闭防火墙或者放开对应的端口
xxxxxxxxxx{"cluster_name": "elasticsearch","status": "green","timed_out": false,"number_of_nodes": 1,"number_of_data_nodes": 1,"active_primary_shards": 0,"active_shards": 0,"relocating_shards": 0,"initializing_shards": 0,"unassigned_shards": 0,"delayed_unassigned_shards": 0,"number_of_pending_tasks": 0,"number_of_in_flight_fetch": 0,"task_max_waiting_in_queue_millis": 0,"active_shards_percent_as_number": 100.0}
集群部署
从地址
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-8-0选中LINUX_X86_64 sha下载指定版本的Linux版本的ES压缩包elasticsearch-7.8.0-linux-x86_64.tar.gz并上传至Linux系统在上传目录使用命令
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz解压缩压缩包,解压后的名字较长,使用命令mv elasticsearch-7.8.0 es-7.8.0-cluster将ES的名字修改为es-7.8.0-cluster在虚拟机ip分别为131和135的机器上再重复解压安装一遍,实际上可以使用命令进行其他机器的文件分发,这个在尚硅谷的Hadoop课程中有讲文件分发,后续补充,这里先试用手动解压的方式安装
为所有es创建操作用户,赋予操作用户对应文件目录的权限,自定义三台主机的主机名
自定义主机名的方法见本文档命令大全中系统操作中的主机名,三台机器136、131、135对应的主机名分别为elasticsearch1、nginx1和elasticsearch3
修改136机器上的配置文件
/opt/elasticsearch/es-7.8.0-cluster/config/elasticsearch.yml136的配置文件
初始默认配置文件全是注释,直接在文件末尾添加以下配置即可
xxxxxxxxxx# 加入如下配置#集群名称cluster.namecluster-es#节点名称, 每个节点的名称不能重复node.namenode-1#ip 地址, 每个节点的地址不能重复network.hostelasticsearch1#是不是有资格主节点node.mastertruenode.datatruehttp.port9200# head 插件需要这打开这两个配置http.cors.allow-origin"*"http.cors.enabledtruehttp.max_content_length200mb#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 mastercluster.initial_master_nodes"node-1"#es7.x 之后新增的配置,节点发现,9300是es内部节点默认的通信地址discovery.seed_hosts"elasticsearch1:9300""nginx1:9300""elasticsearch3:9300"gateway.recover_after_nodes2network.tcp.keep_alivetruenetwork.tcp.no_delaytruetransport.tcp.compresstrue#集群内同时启动的数据任务个数,默认是 2 个cluster.routing.allocation.cluster_concurrent_rebalance16#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个cluster.routing.allocation.node_concurrent_recoveries16#初始化数据恢复时,并发恢复线程的个数,默认 4 个cluster.routing.allocation.node_initial_primaries_recoveries16131的配置文件
相比于136只是修改了节点名称和主机名称
xxxxxxxxxx# 加入如下配置#集群名称cluster.namecluster-es#节点名称, 每个节点的名称不能重复node.namenode-2#ip 地址, 每个节点的地址不能重复network.hostnginx1#是不是有资格主节点node.mastertruenode.datatruehttp.port9200# head 插件需要这打开这两个配置http.cors.allow-origin"*"http.cors.enabledtruehttp.max_content_length200mb#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 mastercluster.initial_master_nodes"node-1"#es7.x 之后新增的配置,节点发现,9300是es内部节点默认的通信地址discovery.seed_hosts"elasticsearch1:9300""nginx1:9300""elasticsearch3:9300"gateway.recover_after_nodes2network.tcp.keep_alivetruenetwork.tcp.no_delaytruetransport.tcp.compresstrue#集群内同时启动的数据任务个数,默认是 2 个cluster.routing.allocation.cluster_concurrent_rebalance16#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个cluster.routing.allocation.node_concurrent_recoveries16#初始化数据恢复时,并发恢复线程的个数,默认 4 个cluster.routing.allocation.node_initial_primaries_recoveries16135的配置
同样相比于136只是修改了节点名称和主机名称
xxxxxxxxxx# 加入如下配置#集群名称cluster.namecluster-es#节点名称, 每个节点的名称不能重复node.namenode-3#ip 地址, 每个节点的地址不能重复network.hostelasticsearch3#是不是有资格主节点node.mastertruenode.datatruehttp.port9200# head 插件需要这打开这两个配置http.cors.allow-origin"*"http.cors.enabledtruehttp.max_content_length200mb#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 mastercluster.initial_master_nodes"node-1"#es7.x 之后新增的配置,节点发现,9300是es内部节点默认的通信地址discovery.seed_hosts"elasticsearch1:9300""nginx1:9300""elasticsearch3:9300"gateway.recover_after_nodes2network.tcp.keep_alivetruenetwork.tcp.no_delaytruetransport.tcp.compresstrue#集群内同时启动的数据任务个数,默认是 2 个cluster.routing.allocation.cluster_concurrent_rebalance16#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个cluster.routing.allocation.node_concurrent_recoveries16#初始化数据恢复时,并发恢复线程的个数,默认 4 个cluster.routing.allocation.node_initial_primaries_recoveries16
每台主机都修改对应的系统配置文件
ES生成的数据和文件比较多,生成文件时使用系统默认配置可能会出一些问题,需要对系统的配置进行修改
使用
vim /etc/security/limits.conf修改文件/etc/security/limits.conf,在文件末尾添加每个进程可以打开的文件数的限制的以下配置xxxxxxxxxx# 在文件末尾中增加下面内容# 每个进程可以打开的文件数的限制es soft nofile 65536es hard nofile 65536使用命令
vim /etc/security/limits.d/20-nproc.conf修改系统配置文件,在文件末尾添加以下配置xxxxxxxxxx# 在文件末尾中增加下面内容# 每个进程可以打开的文件数的限制es soft nofile 65536es hard nofile 65536# 操作系统级别对每个用户创建的进程数的限制* hard nproc 4096# 注: * 带表 Linux 所有用户名称使用命令
vim /etc/sysctl.conf在文件末尾追加配置一个进程可以拥有的虚拟内存的数量xxxxxxxxxx# 在文件中增加下面内容# 一个进程可以拥有的 VMA(虚拟内存区域)的数量,默认值为 65536vm.max_map_count=655360使用命令
sysctl -p重新加载系统配置
修改每个节点所在主机的
/etc/hosts文件这个必须把集群节点所在的所有主机名和ip的映射关系在每一台主机上都要全部写上,如果不写当前主机和对应的ip映射关系,ES节点中
network.host写当前主机的主机名非master的ES节点会直接启动报错,提示以下信息【以前的其他软件集群部署都是在所有节点主机的/etc/hosts文件中写上包括本机在内的完整的节点映射信息】
/etc/hosts文件示例即每个节点所在主机的hosts中都要配置完整集群节点的主机名IP映射,如果当前主机没有配置,非masterES中的
network.host使用当前主机的主机名会直接导致ES启动报错,此时把network.host配置成0.0.0.0能够正常启动,但是不建议这么做,此外一定不能在/etc/hosts中将主机名配置成127.0.0.1的映射关系,会直接导致包括master节点在内的ES服务器无法被访问【连HTTP端口也无法访问】xxxxxxxxxx[es@nginx1 es-7.8.0-cluster]$ cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.200.132 node1192.168.200.133 node2192.168.200.134 node3192.168.200.136 elasticsearch1192.168.200.135 elasticsearch3192.168.200.131 nginx1
切换成对应机器分别切到操作用户按顺序启动三个节点,使用PostMan发送请求
http://192.168.200.136:9200/_cat/nodes【GET】查看节点所在集群的所有节点信息当只有136节点启动时的响应结果
xxxxxxxxxx172.17.0.1 28 96 2 0.06 0.07 0.06 dilmrt * node-1当136和131都启动时的响应结果
xxxxxxxxxx192.168.200.136 55 44 0 0.21 0.12 0.08 dilmrt * node-1192.168.200.131 21 94 4 0.09 0.08 0.07 dilmrt - node-2当136、131和135都启动时的响应结果
xxxxxxxxxx192.168.200.136 55 44 0 0.21 0.12 0.08 dilmrt * node-1192.168.200.131 21 94 4 0.09 0.08 0.07 dilmrt - node-2192.168.200.135 21 96 2 0.04 0.07 0.06 dilmrt - node-3
核心概念
索引
概念
索引就是一个拥有几分相似特征的文档的集合 ,理解成比如订单数据有共同点,这个共同点就可以作为订单数据整体的索引,索引可以更形象的类比为新华字典的索引目录,按首字母排序,同一个首字母下又按照第二个、第三个首字母依次排序,这样的设计是为了加快检索速度
特征
一个索引由一个名字来标识(该名字必须全部是小写字母),当我们要对这个索引中的文档进行索引、搜索、更新和删除的时 候,都要使用到这个名字
在一个集群中,可以定义任意多的索引,能搜索到的数据都必须索引
一个索引可以被分成多片,也可以被复制0次和多次,一旦被复制,索引就有了主分片和复制分片,分片和复制数量可以在索引创建时进行指定,索引创建后可以动态地改变索引复制的数量,但是不能改变索引分片的数量;默认情况下每个索引有一个主分片和一个复制分片,即当集群至少有两个节点时,索引会默认有一个主分片和一个完全拷贝的复制分片
类型
概念
ES早期对应关系型数据库,把索引当成数据库、把类型当成表、把文档当成数据行;后来发现索引就可以直接关联数据,在索引和数据之间再添加一个类型来关联数据显得画蛇添足,在7.x的版本以后就完全抛弃了类型的概念
早期的思路是在一个索引下定义一个或多个类型,一个类型是索引的一个逻辑上的分支,语义由用户自行定义,通常会将由一组共同字段的文档定义为一个类型
文档
概念
文档就是一条数据,一个文档是一个可以被索引的基础信息单元,保存一条数据就是保存一个文档
特征
文档以JSON的格式来表示,JSON是一种通用的互联网数据交互格式,有很多第三方类库都能解析JSON字符串
在一个索引或者类型中可以存储任意数量的文档
字段
概念
JSON格式文档中的属性就是字段,对应数据库表中字段,对文档数据可以根据不同属性进行分类标识
映射
概念
类比于MySQL,表结构信息规定了一张表有哪些字段,字段类型、长度范围、默认值、是否可以为null,索引也会有类似于表结构的概念,比如规定哪些字段可以被查询,哪些字段可以进行分词操作,都有专门的设定;该设定就是映射
即映射是ES中数据的使用规则设置,按最优规则处理数据会极大地提高处理数据的性能
分片
概念
一个索引可以存储超出单个节点硬件限制的大量文档数据,比如一个含有十亿文档数据的索引可能占据1TB的磁盘空间,但是任何一个节点都没有这么大的磁盘空间;或者数据量太大,单个节点处理搜索请求响应太慢;ES针对该问题,提供将索引划分成多份的能力,每一份就是一个分片;比如把用户索引下的文档数据按照性别拆分成两个分片,查询用户数据男性去一个分片查,女性去另一个分片查
创建索引时可以指定该索引想要分片的数量,每个分片本身就是一个功能完善且独立的索引,该索引可以被放置到集群中的任何节点上
特征
索引是分片的集合,当ES在索引中搜索的时候,会发送查询到每一个属于索引的分片上,合并每个分片的查询结果到一个全局的结果集
意义
分片很重要,一方面允许用户水平切割/扩展用户的内容容量,另一方面允许用户在分片上进行分布式的并行的操作,从而提高查询性能和数据的吞吐量
副本
概念
在网络或者云环境中,由于网络或者节点宕机导致或者任何原因导致的查询失败随时都可能发生,需要实现一种故障转移机制,让故障发生时仍然正常运行或者合理服务降级,ES允许创建分片的一份或者多份拷贝,这个拷贝叫复制分片或者副本
意义
复制分片也是一个重要的概念,一方面在节点/分片查询失败的情况下提供高可用性
🔎这点要求复制分片不会与原/主要分片置于同一个节点上
另一方面也能扩展系统的搜索量/吞吐量,因为搜索可以在所有的副本上同时进行
分配
概念
分配是将分片分配给某个节点的过程,包括分配主分片和复制分片,如果分配的是复制分片,该过程还有从主分片复制数据的过程,该过程是由master节点完成的
ES集群原理
系统架构
概念
ES集群是由一个或者多个拥有相同cluster.name配置的ES节点组成, 它们共同承担数据和负载的压力。
🔎当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
主节点通过选举节点产生,负责管理集群范围内的所有变更,例如增加、删除索引,增加、删除节点等。
🔎主节点不涉及文档级别的变更和搜索等操作,即使当集群只拥有一个主节点的情况下,流量的增加也不会因为只有一个主节点而因此成为系统的瓶颈。 任何节点都可以成为主节点。
用户请求可以发送到包括主节点在内的集群中的任意一个节点,任意一个节点都能将用户请求转发到存储所需文档的节点,并收集从各个包含所需文档的节点收集回数据最终返回给客户端
架构图
📌:Master节点上也有分片,为什么上面说master机器不涉及文档级别的变更和搜索
P0、P1、P2表示每个节点上的分片,R0、R1、R2表示每个分片对应的副本,分片和对应副本不能放在同一个节点上
每个分片底层是一个Lucene Index,Lucene是全文检索引擎,每个分片都是一个检索引擎,查询的时候会自动将满足查询条件的多个分片数据合并在一起进行返回
🔎因此文档数据的查询相对复杂一些,文档数据的新增的过程会相对更简单

单节点集群
业务需求
📜:在只包含一个空间节点的集群内创建名为users的索引,分配三个主分片和一个副本
🔎:每个主分片拥有一个副本分片
💡:启动windows集群中的一个ES节点,向HTTP端口发送请求添加索引并设置映射关系
业务实现
启动HTTP端口为1004的ES节点
🔎:ES集群非常地坑,如果此前是三个节点的集群,此时只启动一个节点,即使是master节点也需要删除data目录,否则ES无法被访问,使用master节点也会提示master节点找不到,解决办法仅需删除data目录
使用POSTMAN向节点发送请求
http://127.0.0.1:1004/users【PUT】🔎:users是索引名
请求体JSON
🔎:设置映射参数,
"number_of_shards" : 3,是设置users索引有三块分片,"number_of_replicas" : 1是复制一次
xxxxxxxxxx{"settings" : {"number_of_shards" : 3,"number_of_replicas" : 1}}
特点
当集群是一个单节点集群时【只有一个master节点】,一个索引的三个主分片都会被分配在该一个节点上
通过浏览器插件
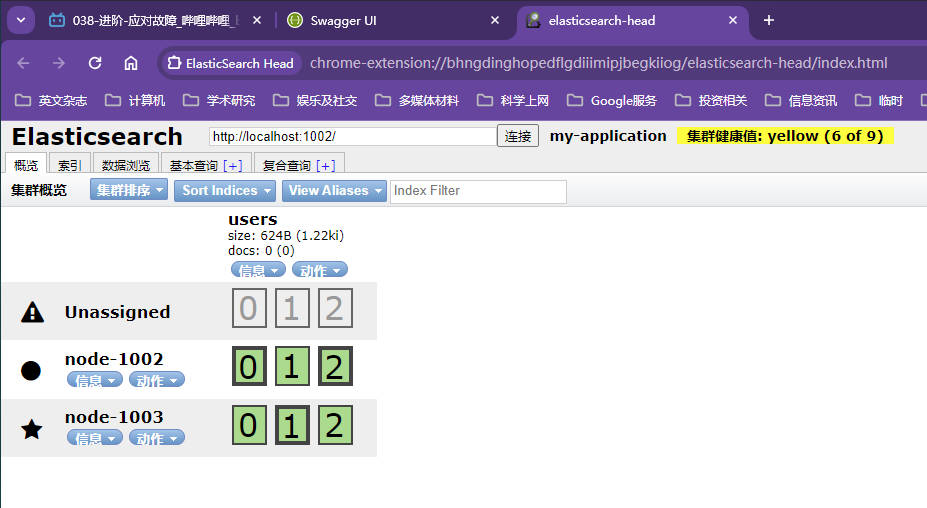
elasticsearch-head可以查看集群的状态,将插件压缩包elasticsearch-head-chrome-plugin.rar解压缩并安装到浏览器上,点开该插件输入ES的端口号点击连接集群健康值:yellow(3 of 6)表示当前集群的全部主分片都正常运行,但是副本都不正常以下三个副本都处于标灰状态,且都提示为
Unassigned,即未分配状态;同一个节点既保存原始数据又保存副本是没有意义的,因为该节点发生硬件故障时,副本也是没有办法使用的;所以该状态也表示集群正常运行,但是应该故障时有丢失数据的风险

单点故障问题
集群中只有一个master节点运行时,因为没有冗余节点,一旦发生故障,数据就会有丢失的风险,此时需要再启动一个节点来做冗余
启动第二个节点加入到集群,通过插件发现三个副本分片都被分配在新加节点,所有新增的被索引的文档都会保存在主分片上,然后被并行地复制到对应的副本分片
📌:注意此时直接启动第二个节点会直接抛异常,因为此前的集群状态是3个节点
🔑:此时需要删除第二个节点的data目录,第一个节点启动时删除data目录即可,此时第一个节点不需要做任何操作
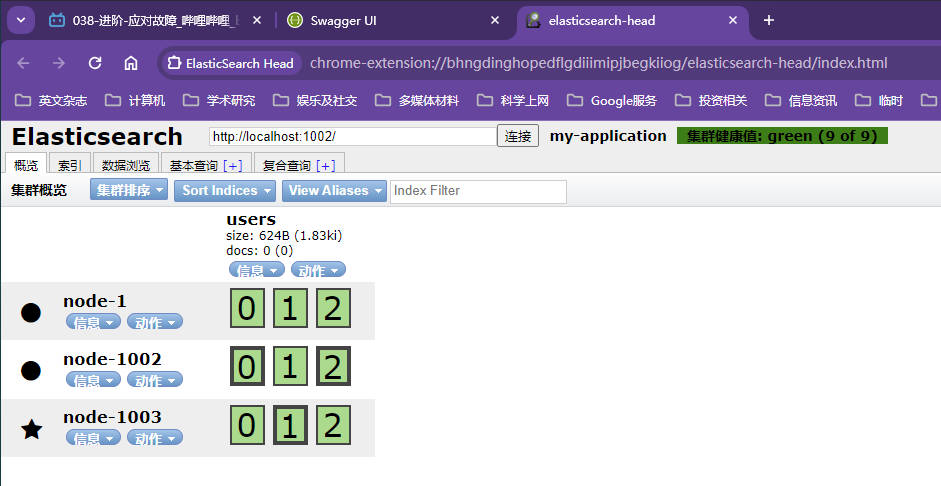
集群状态
第二个节点加入集群后,3个副本分片自动分配到该节点,星号标记的节点是master节点
绿色文字
集群健康值: green (6 of 6)表示所有分片都正常运行,my-application是集群名字🔎:特别注意这里的3个主分片都位于同一个节点【并没有详细说明主分片在节点上的分布行为,关注一下,目前没有任何状态表明master节点上的全是主分片,课程提了一嘴主分片的边框是粗边框,这意味这三个主分片位于同一个master节点】,具体地对文档数据操作是优先使用主分片数据还是同时可以使用复制分片上的数据暂时还没有明确

集群水平扩容
节点水平扩容
双节点集群的默认行为是主分片位于master节点,复制分片位于第二个节点,当启动第三个节点加入集群,ES会为了分散负载主动对分片进行重新分配
📌:第三个节点的启动同样需要删除data目录
🔎:分配遵从两个原则,一是主分片和副本不能位于同一个节点,二是分片的分布应该尽量均匀,但是分片的分配还是ES集群自动决断的
扩容后集群状态
📌:感觉这不是很好的分配策略,为什么不是三个节点上都各分配一个主分片和一个复制分片,这不是更加合理吗?如果副本分片也可以同时进行使用,那么从节点上的分片数量上来看这种分配也合理,每个节点的硬件资源【CPU、RAM、I/O】被更少的分片共享,系统的性能会得到提升
🔎:而且和课程的不一样,课程是主分片2放在了新增节点,实际测试是主分片1放在了新增节点

副本分片可以处理数据
课程后续提到,读操作的搜索和返回数据可以同时被主分片或副本分片处理,所以当你拥有越多的副本分片时,系统也将拥有越高的吞吐量,所以分片分配只需要保证主分片和复制分片不在同一个节点上,所有分片的平均分片数量保持均匀即可【增加副本只能增加读的性能,写的能力主要还是基于主分片】
扩充分片数量
当分片数量小于节点数时,意味着肯定有节点无法被分配分片,这种情况是不被允许的,在索引创建的时候分片数量就已经确定了,此时在不添加索引的情况下,分片数量是固定的,添加新的节点会遇到困难
因为副本分片也可以同时和主分片一样用于查询操作,所以可以通过增加复制次数达到增加分片数量的目的,此时就可以继续添加新的节点来提高系统的吞吐量
发送请求
http://127.0.0.1:1004/users/_settings【PUT】来重新设置主分片被复制的次数请求体JSON
xxxxxxxxxx{"number_of_replicas" : 2}
集群状态

应对集群故障
当master宕机后的集群状态
此时master节点迁移到第二个节点上,主分片也被重新指定,相当于少了一份副本分片
重启第一个节点后的集群状态
第一个节点需要配置集群内其他节点的内部通信地址
discovery.seed_hosts: ["localhost:9303","localhost:9302"]才能在重启以后自动发现并加入集群,注意yml的冒号后面必须有空格,否则启动报错快速失败原来的master节点被永久的重新选举,宕机的节点恢复后以全新的节点加入集群,master节点只有再次宕机后才会重新进行选举,同时主分片只有所在节点宕机后才会重新指定
路由计算
保存数据时的路由计算
当用户需要插入一条数据如
zhangsan,需要先将文档数据写入对应索引下的其中一个主分片,然后再拷贝到对应的复制分片,ES集群是如何决断将该文档数据路由到哪一个主分片呢,ES集群根据自己的内部规则对文档数据进行主分片路由,这个规则就叫路由计算路由计算的规则为hash(文档数据id)%主分片数量=【0,1,2】
shard表示某一个分片、number_of_primary_shards表示主分片数量
routing表示路由参数,通过该文档可以自定义文档到分片的映射,通过自定义该路由参数可以保证相关文档如同属于一个人的文档数据都存储到一个分片中,默认是文档数据的主键id
示意图

查询数据时的路由计算
分片控制:用户可以访问任何一个节点来获取数据,因为存放规则是固定的,用户访问的这个节点称为协调节点
一般情况下系统的分片控制规则是轮询,分片控制意思是用户访问节点的负载均衡策略,因为任意一台机器都能转发请求获取到数据,通过主键id取哈希对主分片数量取模就能得到主分片位置进而转发请求获取数据,而采用轮询的策略能够避免在用户请求层面发生流量倾斜的情况
写数据流程
用户请求发送给集群时并不知道数据会写到哪个分片,到达集群上某个节点后经过计算才知道数据将被写入到具体哪一个主分片
新建、索引、删除文档数据的流程
1️⃣:客户端发送新建、索引、删除请求到任意集群节点
🔎:该节点称为协调节点
2️⃣:协调节点通过路由计算将请求转换到指定主分片所在节点
3️⃣:主分片将数据保存
4️⃣:主分片将数据并行发送到各个副本
5️⃣:副本保存后将保存结果进行反馈
📌:反馈到主分片还是协调节点,暂时认为是主分片
🔑:经过文档确认是反馈到主分片所在节点
6️⃣:主分片将保存结果进行反馈
📌:反馈给客户端还是协调节点,暂时认为是协调节点
🔑:经过文档确认是反馈到协调节点
7️⃣:协调节点向客户端反馈结果,客户端获取写数据反馈
设置可选请求参数
以上的流程是完整的写数据流程,一些可选的请求参数允许用户影响该流程,比如在主分片保存数据成功后就可以开始直接请求数据,因为ES的性能已经很高了,这些设置请求参数的操作很可能以数据安全为代价提升系统性能,所以这些选项实际上很少使用
consistency参数值:
"consistency" : ["quorum"|"one"|"all"]默认值:
"consistency" : "quorum"配置说明:满足指定数量活跃可用的分片副本主分片才能执行写操作
🔎:
"consistency" : "one":只要主分片活跃就允许执行写操作;"consistency" : "all":必须要主分片和所有复制分片都活跃才允许执行写操作;"consistency" : "quorum":规定数量的分片副本【分片副本包含了主分片和复制分片】活跃就允许执行写操作🔎:默认配置即
"consistency" : "one"下,在仅仅视图写操作之前,主分片都要求必须有规定数量的活跃分片副本,才会执行写操作,这种设计是为了避免发生网络分区故障时进行写操作导致不同分区的数据不一致,规定数量的计算公式是🔎:
number_of_replicas指的是在索引设置中的设定副本分片数,而不是指当前处理活动状态的副本分片数,如果索引设置中规定当前索引拥有三个副本分片,规定数量为((1+2)/2)+1=3【primary暂时认为是主分片数量】,此时如果只启动两个节点,处于活跃状态的分片副本只有2,达不到规定数量,此时将无法索引和删除任何文档
🔎:新索引默认有一个副本分片,在默认配置下意味着为满足规定数量需要两个活跃的分片副本,显然这种默认设置会阻止用户在单一节点上做任何事情,为了避免该问题,默认配置的规定数量计算公式只会在指定
number_of_replicas副本分片数大于1的情况下才会执行
timeout参数值:
"timeout" : 100默认值:
"timeout" : 60s配置说明:没有足够副本分片的情况下Elasticsearch的最长等待时间
🔎:如果没有足够的副本分片,Elasticsearch会进行等待,期望更多的分片出现
🔎:默认配置下Elasticsearch最长等待一分钟,可以通过设置timeout参数来使得等待更早终止,默认单位是毫秒,即
"timeout" : 100表示等待时间为100ms,也可以通过"timeout" : 30s来指定最长等待时间为30秒
读数据流程
获取文档数据的流程
1️⃣:客户端向任意一个节点发起查询请求,该节点被称为协调节点
2️⃣:协调节点通过文档id计算文档数据所在的主分片和对应的全部复制分片位置
3️⃣:采用轮询的负载均衡策略来轮询所有的分片副本【包含主分片和所有的副本分片】
🔎:当文档被检索时,已经被索引的文档可能已经存在于主分片上但是还没有复制到副本分片上,这种情况下副本分片可能会报告文档不存在,但是主分片仍然能成功返回文档,
4️⃣:分片节点将数据返回给协调分片,协调分片将结果返回给客户端
更新数据流程
更新数据的流程

1️⃣:客户端向任意一个协调节点发送更新请求
2️⃣:协调节点根据文档数据的id计算主分片所在节点位置,将更新请求转发到主分片所在的节点
3️⃣:主分片检索文档,修改文档内容,并尝试重新索引主分片中的文档;如果当前文档正在被另一个进程修改,当前进程无法拿到文档的锁,会一直重试步骤3,直到超过
retry_on_conflict次后放弃4️⃣:如果主分片被成功更新,主分片会将新版本文档并行地转发到全部的副本分片,副本分片更新文档并重新建立索引
5️⃣:一旦副本分片都返回成功,主分片节点会向协调节点返回更新成功,协调节点向客户端返回更新成功
要点
主分片并行将更改转发到副本分片时,不会转发更新请求,而是转发完整文档的新版本
这些更改会被异步地转发到副本分片,无法保证更改请求以发送的顺序到达副本分片,如果仅仅是转发更改请求,则可能导致以错误顺序应用前后两次更改,导致文档被损坏
👅:转发文档的最新版可能使用乐观锁检查记录数据的版本来避免数据的更新顺序错误,这只是本人臆测,原教学文档没有提及此事
多文档操作流程
单个mget请求取回多个文档数据的步骤

1️⃣:客户端向协调节点发送mget请求
2️⃣:协调节点为涉及的每个分片构建多文档获取请求,并行地转发这些请求到主分片或者副本分片的节点上,收到这些节点的答复后,汇总这些答复构建响应并返回给客户端
❓:请求主分片和副本分片的行为没有说明
👅:感觉还是像单个查询请求一样在协调节点直接轮询所有的分片副本,而不是单独将请求发送给主分片,由主分片负责后续的查询工作
单个批量请求bulk API中执行多个创建、索引、删除和更新请求

1️⃣:客户端向协调节点发送bulk请求,协调节点解析请求为每个主分片所在节点创建一个批量请求,将这些批量请求并行转发到包含主分片的节点
2️⃣:所有相关主分片按顺序执行每个操作,每个操作执行成功时主分片并行转发完整新文档到对应所有副本分片,然后执行下一个操作
3️⃣:当所有副本分片执行成功并报告给主分片,主分片向协调节点报告执行成功,协调节点将响应收集并返回给客户端
分片原理
分片是Elasticsearch中的最小工作单元,对文档数据的检索和写操作都是基于分片完成的,一个索引的数据量太大以后会影响文档查询的效率,把一个大的索引拆成几个部分,每个部分叫一个分片;每个分片组合在一起就是一个完整的索引数据;写入完成以后分片会进行一个倒排索引的建立,在查询中使用倒排索引快速查询到文档数据;Elasticsearch底层是Lucene,Elasticsearch的倒排索引就是Lucene的倒排索引
倒排索引
概念
传统数据库每个字段都存储单个值,但是全文检索中文档中字段的每个词都要被搜索,对数据库来说要求单个字段具有索引多值的能力,满足一个字段多个值需求的最好的数据结构是倒排索引,也叫倒向索引,倒向索引还有对应的正向索引
👅:实际上满足一个字段多个值的数据结构也包含正向索引,只是正向索引无法满足实时排名结果或者更高相关性的需求,不可能遍历每篇文档找到其中的关键词来判断是否相关,由此需要更好的倒排索引,即根据关键词来匹配更吻合的文档
正向索引:搜索引擎将待搜索的文件和一个文件id对应形成k-v键值对,然后针对文档对文档中的关键词进行统计计数
🔎:这种方式在搜索引擎上天文数字一般的文档数目条件下,无法满足实时返回排名结果的需求,搜索引擎会将正向索引重新构建为倒排索引

倒排索引:将正向索引的文件ID对应关键词的映射转换为关键词到文件id的映射,每个关键词对应一系列的文件,这些文件中都出现该关键词

倒排索引示例
📜:对以下两个文档进行倒排索引
The quick brown fox jumped over the lazy dog
Quick brown foxes leap over lazy dogs in summer
💡:一个文档的倒排索引由文档中所有不重复词的列表构成,即每个不重复词都作为关键词,含有对应关键词的文档的id作为关键词值列表的一个元素,这样的关键词叫词条或者tokens【词条是索引中最小存储和查询的单元,英文文档中一般是一个单词,中文文档中一般是一个词组】,这个过程叫做分词,分词有专门的分词器,对中文和英文的分词器的分词规则是不同的,词条的集合被称为词典,词典一般有两种数据结构,一种是B+树,还有一种是HashMap
倒排索引的过程
先拿着检索词条去词典中检索是否存在,如果存在再去倒排表中检索词条对应的文档id的列表,拿着文档id进行匹配并拿到相关的文档数据
两个文档所有的不重复词条的排序列表【倒排表】
🔎:分词也会有一定策略,根据不同的业务需求不一定提取所有的不重复词,可能只抓人名等关键词,还有可能人名按需求会继续拆分出姓和名作为额外的索引词条,而且根据字段类型分词的策略也不同,当字段类型为keyword时对应值是不能进行分词的,需要完全匹配;如果字段类型是文本,就需要按照分词器的规则进行分词
🔎:此外分词还可以设置ik分词器的不同分词算法,
ik_max_word【表示对文档按照最细腻度的方式进行分词】和ik_smart【表示对文档按照最粗粒度的方式进行分词】

此时搜索词条如
quick brown,只需要查找对应词条包含的文档,每个词条都包含的文档或者词条匹配度最高的文档就是最相关的文档,在这种简单情况下,文档1的相关度比文档2高
但是这种方式也存在问题,用户可能不认为单词的大小写有区分或者用户记错了对应关键词是大写还是小写;用户也可能压根就不记得关键词是单数还是复数,又或者具有相同词根但是形式不同的词;还有可能用户要表示jump的意思,但是确记成了leap或者不是相同词根但是意思相近的其他单词;在用户非常自信的检索关键字
+Quick +fox【+前缀表示文档中必须出现该词条】,此时文档1为quick fox而文档2为Quick foxes导致用户不会查询到任何结果,这是很不友好的,为此发展出了以下的标准化解决方式核心是文档词条和查询字符串都必须标准化为相同的格式
创建倒排索引的时候将关键字即词条规范为标准模式【如将词条统一为小写,将词汇统一提取为词根的格式,将同义词统一索引为相同的单词等,可能还会将文档中的姓名按姓和名拆分】,此时的文档对应的词条排序列表如下所示

此时索引中不会在出现首字母大写的单词如Quick了,当直接使用用户搜索的词条Quick来匹配索引词条也会失败,因此用户检索的词条也需要和文档数据一样使用相同的标准化规则转换为
+quick +fox的形式,这样两个文档都会匹配
文档搜索
背景
倒排索引的一个特点是被写入磁盘后是不可改变的,倒排索引的不变性会带来以下好处
只要不更新索引,就不需要担心高并发多线程是多进程同时修改索引数据的问题,就不需要额外日常加锁
因为磁盘的索引不会更新,索引被读入内核的文件系统缓存就会留在缓存即内存中而不需要关注索引的更新问题,此时大部分请求会直接请求内存,不会命中磁盘,会极大地提升系统性能
其他和索引相关的缓存,如filter缓存,因为一个生命周期内索引数据不会发生变化,这些缓存数据也不会发生变化
写入单个大的倒排索引允许数据被压缩,减少磁盘I/O和内存的使用量
早期的全文检索会为整个文档建立很大的一个倒排索引并写入磁盘,直到新的索引被创建,旧的索引会被直接替换,即写入磁盘的倒排索引不会发生改变
这种方式虽然有索引不变性带来的好处,但是一旦需要添加一个新的可被索引和搜索的文档,需要重建整个倒排索引,这对索引可被更新的频率有非常大的限制,也因此对索引的数据量造成很大地限制
动态更新索引
要保证倒排索引的不变性还要实现倒排索引的更新,解决办法是将最新时间的写操作全部写入一个新的倒排索引中,用来补充最近的修改,Lucene这个java库引入按段搜索的概念,每一段都是一个倒排索引,整个索引就是所有段的集合,将所有已知段列举在一个称为提交点的文件中
按段搜索流程
1️⃣:新文档被搜集并建立索引到内存索引缓存中
2️⃣:缓存不时被提交,提交时一个新的段即一个追加的倒排索引被写入磁盘,一个包含新段名字的提交点被写入磁盘,所有文件系统缓存中等待的写入都被刷新到磁盘
3️⃣:新的段开启,其中包含的文档也可以被搜索
4️⃣:内存缓存被清空,等待接收新的文档
搜索流程
当一个查询被触发,所有已知的段按顺序被查询,此项统计对所有段的结果进行聚合
段是不可改变的,既不能删除旧的段中的文档,也不能修改更新旧段中的文档,取而代之的是在每个提交点包含一个
.del后缀文件,该文件中包含被删除文档的段信息,即一个文档被删除仅仅只是在.del文件中被标记删除,实际查询时被删除的文档仍然会被检索匹配到,但是会在最终结果被返回前从结果集中被剔除,文档更新也是标记删除旧文档,新版本文档被索引到一个新段中,两个版本的文档都可能被一个查询匹配到,但是旧版本文档在结果集返回以前会从结果集中被剔除此外段还有合并的概念,当多个段进行合并的时候,会将标记删除的索引和文档真正地进行物理删除,避免文档数据的过度冗余存储
近实时搜索
不带文件系统缓存的写操作流程
之前讲过了,大致总结
客户端请求打到协调节点,协调节点计算主分片所在节点位置,转发写请求到主分片,主分片写操作结束转发完整更新后文档到所有的复制分片,每个复制分片写成功响应成功信息给主分片,主分片收到所有响应成功信息后将写入成功的信息响应给协调节点,协调节点响应成功信息给客户端
此时,系统写入文档的延时是主分片写入延时+并行写入副本的最大延迟
🔎:副本分片越多,数据越安全,但是可能发生的最大延迟事件可能更长【可能网络带宽资源占用越多吧】
此时写入是在内存中创建索引,将索引加入内存的段中,只有段被写入磁盘以后文档数据才能供用户查询【那文档第80页上面为什么说内存中的新的段被开启,让它包含的文档可见以被搜索】,段被写入磁盘的过程被称为flush
❓:啊?这里说这个新的段被flush到磁盘以后才会返回保存成功给客户端,那不是每个写操作都要创建一个新段并写入磁盘?
🔑:这里是老师为了引入后续的近实时搜索进一步优化引出的内容,即这不是最终形态,因为每次对文档进行写操作都要将段写入磁盘文档才能被索引,
👅:这里感觉应该理解成文档需要被存储到磁盘上,同时建立文档索引,此时才能通过索引找到文档的位置,从而将文档从磁盘响应给用户
这种方式存在问题,通过这种方式每次添加文档都要将段通过fsync函数将缓冲区的数据立即写入磁盘,通过这样来保证断电的情况下尽可能不丢失数据,但是fsync操作的代价很大,每次索引一个文档都去执行一次会造成很大的性能问题
🔎:此时,发展出一种在Elasticsearch和磁盘件使用文件系统缓存来解决使尚未刷新到磁盘的文档能被搜索以及拉长新的段被fsync到磁盘的时间间隔,同时还要能保证数据的安全性,在即使突然断电的情况下也能尽可能地保全文档数据
带文件系统缓存的写操作流程
1️⃣:内存索引缓冲区中的文档被写入到一个新的段中,然后这个新段会先写入文件系统缓存,稍后再被刷新到磁盘中
🔎:写入文件系统缓存的代价比刷新到磁盘的代价低,且文件系统缓存中的文件可以向磁盘上的文件一样被打开和读取,通过文件系统缓存就可以使新段包含的文档在未进行一次完整提交时便对搜索可见
🔎:这种将文档写入新段和文件系统缓存并打开一个新段的过程叫refresh,每个分片每秒会自动刷新一次,这也是Elasticsearch近实时搜索的含义,指的是对文档的写操作【新建、索引、删除文档数据】后文档并不是立即对搜索可见,但是会在一秒内变得可见
🔎:当索引一个文档后很快地尝试搜索该文档,结果发现搜索不到,此时的解决办法是通过URI:/users/_refresh调用refresh API来执行一次手动将新段刷新到文件系统缓存【users是索引】,可以在测试的时候使用手动刷新,但不要在生产环境每次索引一个文档就去手动刷新,因为尽管刷新比提交少了很多操作,但是还是有性能开销
🔎:并不是所有的情况都需要每秒刷新,使用Elasticsearch索引大量日志文件,此时应该重点优化索引速度,而不是近实时搜索,可以通过设置参数
refresh_interval来降低新段刷新的频率,比如设置成30s刷新一次【理解成30s做一次检查,新段有写入数据就将新段写入文件系统缓存】,因为降低刷新频率能在一个新段上建立更大的倒排索引,而且过程中省去很多刷新开销,在生产环境建立一个大的新索引时也可以通过设置"refresh_interval": -1来关闭自动刷新功能🔎:设置刷新间隔
设置刷新间隔为30s
xxxxxxxxxx{"settings": {"refresh_interval": "30s"}}关闭自动刷新,发送请求
/users/_settings【PUT】xxxxxxxxxx{ "refresh_interval": -1 }将刷新时间调整为默认值,发送请求
/users/_settings【PUT】xxxxxxxxxx{ "refresh_interval": "1s" }
持久化变更
概念
动态更新索引,一次完整的提交会将段刷新【flush】到磁盘并将提交的段写入一个包含所有段列表的提交点,如果没有fsync将数据从文件缓存系统刷新到硬盘,无法保证数据在程序正常退出或者断电的情况下依然存在
在完整提交来确保数据的安全性外,我们还需要方案来确保两次提交之间文件系统缓冲的数据不会因为意外情况而发生丢失,由此衍生出了一个名为translog的事务日志,每一次对Elasticsearch进行操作时都会进行日志记录
完整的一次提交流程
1️⃣:一个文档被索引后会被添加到内存缓冲区,然后立即追加translog对应的事务日志,注意是文档先添加到内存然后再添加日志
🔎:translog日志的作用是为还没有被刷新到磁盘的操作提供一个持久化记录,当ELasticsearch启动后,会从磁盘中使用最后一个提交点去恢复已知的最后一个段,并且重新执行translog中在最后一次提交后发生的变更操作,ELasticsearch在尝试恢复或者打开一个索引是,也会需要重放translog中的所有操作,日志越短,恢复越快,在重启节点或者关闭索引前执行手动flush的操作有益于重新打开或者恢复一个索引;
🔎:在通过文档ID查询、删除、更新一个文档时,在尝试从相应的段中检索前会先检查translog中最近的变更来保证实时获取文档的最新版本
🔎:默认情况下,translog每5秒钟就会被fsync刷新到硬盘,每次写请求【index, delete, update, bulk】完成之后主分片和复制分片也会执行fsync操作,当主分片和复制分片的translog被fsync到磁盘以后才会响应200OK给客户端 ;每次写操作请求后执行一个fsync会带来性能损失,bulk导入的fsync的性能开销相对其他较小,因为其在一次请求中平摊了大量文档的开销
🔎:对于一些大容量偶尔丢失几秒数据无所谓的集群,可以考虑使用异步translog的fsync,即每次写操作以后都不进行日志的flush,只选用每5秒自动执行一次fsync,使用这种方式需要保证当集群发生崩溃时,丢失掉
sync_interval时间段中的数据也无所谓,如果不能确定丢失数据的后果,最好是使用默认的参数"index.translog.durability": "request"来避免数据丢失
2️⃣:refresh使分片每秒被刷新一次,整个刷新过程依次为
内存缓冲区文档被写入一个新的段且没有进行fsync操作
👅:感觉像段不是写入内存缓冲区,而是文档写入内存中的段,内存中的段不会以新的形式写入文件系统缓存,而是像一种注册的行为,让内存中段的数据能像文件一样被打开和读取,而刷新操作就是将内存缓冲区中的文档内容刷新追加到这个内存中的段中
👅:卧槽,下面段合并说自动刷新流程每秒会创建一个新的段,现在只能认为每次refrush都会创建一个新的段,每次都将新段写入系统文件缓冲,最后提交的时候提交了非常多的段
被刷新的段被打开,段内文档对搜索可见
内存缓冲区被清空
3️⃣:更多的文档重复上述过程追加到该段中,操作不断被追加到事务日志中
4️⃣:当间隔一段时间或者事务日志累计到一定程度,索引被刷新【flush】,一个新的translog被创建,一个全量提交被执行,整个过程依次为
执行一个提交并且节点translog的行为叫做flush,分片每30min会进行一次自动刷新,或者当translog太大时也会自动进行刷新
所有内存缓存区的文档被写入一个新的段
内存缓冲区被清空
一个提交点被写入硬盘
文件系统缓存通过fsync被刷新到磁盘
老的translog事务日志被删除
段合并
概念
自动刷新流程refrush每秒都会创建一个新的段,段数目太多会导致文件句柄、内存和CPU运行周期消耗较大,此外每个搜索请求都要轮询检查每个段,段越多搜索速度就越慢,ELasticsearch通过段合并来解决这个问题,将小的段合并到大的段,将这些大的段合并到更大的段,段合并过程中将旧的已经删除的文档从文件系统中清除,在一个段中被删除的文档不会被拷贝到新的大段中
在创建索引和搜索时会自动启动段合并
合并过程中会选择部分大小相似的段,在后台将这些段合并到更大的段中
👅:感觉像从文件系统缓冲将段合并成一个大段
段合并结束老的段会被删除,新的段被刷新flush到磁盘,写入一个包含新段且排除旧的和较小的段的新提交点
新的段被打开用来搜索,老的段被删除
合并段需要消耗大量I/O和CPU资源,ELasticsearch在默认情况下对合并流程会进行资源限制,让搜索有足够的资源高效进行
文档分析
分析包含两个过程,将一块文本分成合适于倒排索引的独立词条,将这些词条统一为标准格式提高这些词条的可搜索性
分析器
分析器在执行分析过程时实际上封装了以下三个功能,分析器就是一个包中组合了以下三种函数的一个包装器,分析器将三种函数按照顺序执行
字符过滤器
字符串按顺序通过一系列字符过滤器,HTML清除字符过滤器能用来去掉所有的HTML标签等字符,并且像把Á转换为相对应的Unicode字符Á,或者将一些特殊含义的字符如&转换成and等
一个分析器可能有 0 个或者多个字符过滤器
分词器
字符串被分词器分成单个词条,最简单的分词器遇到空格和标点时将文本拆分成词条,正则分词器根据匹配正则表达式来分割文本,关键词分词器完整输出接收到的字符串,不做任何分词
一个分析器必须有且只有一个唯一的分词器
Token过滤器
分词器拆分出来的词条按顺序通过每个token过滤器,该过程可能会改变词条如将英文字母改成全部小写,删除a、and、the等无用词条,增加jump、leap等同义词词条
ES提供很多词单元过滤器,lowercase词过滤器将词条小写,stop过滤器是一个停用词过滤器【删除】,词干过滤器把单词转换成词干,
ascii_folding过滤器移除变音符【把一个像très这样的词转换为tres】,ngram和edge_ngram词单元过滤器可以产生适合用于部分匹配或者自动补全的词单元
内置分析器
Elasticsearch附带了可以直接使用的预包装的分析器,以下是最重要的几个分析器,以下演示分析器处理下列文档的效果:"Set the shape to semi-transparent by calling set_trans(5)"
标准分析器
标准分析器是Elasticsearch默认使用的分析器,根据Unicode联盟定义的单词边界划分文本,删除绝大部分标点,最后将词条全部小写,该分析器是分析各种语言文本最常用的版本,产生的对应词条:
set, the, shape, to, semi, transparent, by, calling, set_trans, 5
简单分析器
在任何不是字母的地方分隔文本,并将词条小写,产生的对应词条:
set, the, shape, to, semi, transparent, by, calling, set, trans
空格分析器
在空格的地方划分文本,产生的对应词条:
Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
语言分析器
特定的语言分析器可以考虑指定语言的特点,如英语分析器会删除对相关性没有影响的英语无用词如the、and等,还可以理解英语语法规则,提取英语单词的词干【transparent、 calling 和 set_trans 已经变为词根格式】,产生的对应词条:
set, shape, semi, transpar, call, set_tran, 5
分析器使用场景
一方面索引一个文档时,需要将文档的全文域使用分析器分析成词条来创建倒排索引,同时用户在全文域搜索的时候,需要将查询字符串使用相同的分析器经过相同的分析过程来保证搜索的词条格式和索引的词条格式一致,但是当用户查询一个精确值域查询的时候,不会分析查询的字符串,而是搜索指定的精确值
区分全文域和精确值域,全文域会对查询字符串和文档做相同的分析过程来保证搜索词条和索引词条格式的一致,精确值域不会分析查询字符串,会直接搜索指定的精确值
❓:精确值域使用什么分析器呢?
测试分析器
使用analyze API查看文本是如何被分析的
使用请求
http://localhost:9200/_analyze【GET】可以查看文本如何被分析请求体json
analyzer指定分析器,text指定要分析的文本xxxxxxxxxx{"analyzer": "standard","text": "Text to analyze"}响应结果
token是实际存储到索引中的词条,position指词条在原文本中出现的位置即从1开始的第几个词,start_offset和end_offset分别指明字符在原始包含空格字符串中的起始字节位置和字节结束位置,以空格作为一个词的结束且位置下标从0开始xxxxxxxxxx{"tokens": [{"token": "text","start_offset": 0,"end_offset": 4,"type": "<ALPHANUM>","position": 1},{"token": "to","start_offset": 5,"end_offset": 7,"type": "<ALPHANUM>","position": 2},{"token": "analyze","start_offset": 8,"end_offset": 15,"type": "<ALPHANUM>","position": 3}]}
指定分析器
Elasticsearch在文档中检测到一个新字符串域会自动设置该文档为一个全文字符串域,自动使用标准分析器对其进行分析,如果我们想自己指定适用实际数据使用的语言需要的分析方法,想要一个字符串域就是一个字符串域【不使用分析,直接索引传入的精确值】或者文档内部的状态域,需要要手动指定这些域的映射
这里没说怎么指定文档索引时使用哪种分析器,只说了如何制定测试时的分析器
标准分析器的缺点
ES默认的标准分析器无法识别中文中的词汇,只是简单滴将每个字拆到底作为一个词条,这种方式不符合实际的使用需求,一般使用对应ES版本的中文分词器如IK中文分词器
标准分析器分析"测试单词"的分词效果
xxxxxxxxxx{"tokens": [{"token": "测","start_offset": 0,"end_offset": 1,"type": "<IDEOGRAPHIC>","position": 0},{"token": "试","start_offset": 1,"end_offset": 2,"type": "<IDEOGRAPHIC>","position": 1},{"token": "单","start_offset": 2,"end_offset": 3,"type": "<IDEOGRAPHIC>","position": 2},{"token": "词","start_offset": 3,"end_offset": 4,"type": "<IDEOGRAPHIC>","position": 3}]}
IK中文分词器
安装IK中文分词器
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.8.0下载
elasticsearch-analysis-ik-7.8.0.zip解压后将文件夹放在ES根目录下的
plugins目录,重启ES集群中的每个节点都要弄,ES动不动就启动出问题,不要拿不确定去赌未知
使用IK中文分词器进行测试
发送请求
http://localhost:9200/_analyze【GET】添加查询参数"analyzer":"ik_max_word""analyzer":"ik_max_word":会将文本做最细粒度的拆分,注意是按照词组的最细腻度,不会拆分成单个字,只有完全没有词组的情况下才会拆分成单个字"analyzer":"ik_smart":会将文本做最粗粒度的拆分
xxxxxxxxxx{"text":"测试单词","analyzer":"ik_max_word"}对应的分词测试响应效果
xxxxxxxxxx{"tokens": [{"token": "测试","start_offset": 0,"end_offset": 2,"type": "CN_WORD","position": 0},{"token": "单词","start_offset": 2,"end_offset": 4,"type": "CN_WORD","position": 1}]}
扩展词汇
对于分词器无法识别的词汇如"弗雷尔卓德",IK分词器会尝试将每个字都分开作为单独的词条,用户可以尝试在
plugins/ik/config目录下创建custom.dic文件,在文件中写入自定义词汇弗雷尔卓德,每个节点都要添加;同时打开
IKAnalyzer.cfg.xml文件,将新创建的custom.dic文件通过以下配置加入到IK分析器中,重启ES服务器该文件已经写好模板,只需要将
custom.dic添加到用户扩展字典处即可,每个节点都要添加xxxxxxxxxx<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">custom.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>再次发送请求
http://localhost:9200/_analyze【GET】请求体json
xxxxxxxxxx{"text": "弗雷尔卓德","analyzer":"ik_max_word"}响应json
xxxxxxxxxx{"tokens": [{"token": "弗雷尔卓德","start_offset": 0,"end_offset": 5,"type": "CN_WORD","position": 0}]}
自定义分析器
ES中的自定义分析器是组合分析器的三大不同类型的函数,包括字符过滤器、分词器、词单元过滤器来组装出适用于自用场景的分析器
发送请求
http://localhost:9200/my_index【PUT】通过创建索引my_index同时指定使用的自定义的分析器my_analyzer请求体JSON
讲的太粗糙了,以后自己研究一下
上面的
"char_filter"是在其中定义到可能用到的自定义字符过滤器,这里的&_to_and是mapping类型,规定将&转换为and字符的上面的
"filter"是定义可能用到的自定义词单元过滤器,这里的my_stopwords是stop类型,规定删除词条中的the和a词条下面的
"analyzer"是指定自定义的分析器,分析器的名字叫"my_analyzer","type"是custom,表示自定义,"char_filter"指定分析器的所有字符过滤器数组【包括ES自身带的和用户在上面自定义的】,"tokenizer"是指定分词器,"filter"是指定分析器的所有词单元过滤器数组
xxxxxxxxxx{"settings": {"analysis": {"char_filter": {"&_to_and": {"type": "mapping","mappings": [ "&=> and "]}},"filter": {"my_stopwords": {"type": "stop","stopwords": [ "the", "a" ]}},"analyzer": {"my_analyzer": {"type": "custom","char_filter": [ "html_strip", "&_to_and" ],"tokenizer": "standard","filter": [ "lowercase", "my_stopwords" ]}}}}}
索引创建后发送analyze API来测试自定义分析器
发送
http://127.0.0.1:9200/my_index/_analyze【GET】测试新的自定义分析器请求体JSON
xxxxxxxxxx{"text":"The quick & brown fox","analyzer": "my_analyzer"}响应效果
xxxxxxxxxx{"tokens": [{"token": "quick","start_offset": 4,"end_offset": 9,"type": "<ALPHANUM>","position": 1},{"token": "and","start_offset": 10,"end_offset": 11,"type": "<ALPHANUM>","position": 2},{"token": "brown","start_offset": 12,"end_offset": 17,"type": "<ALPHANUM>","position": 3},{"token": "fox","start_offset": 18,"end_offset": 21,"type": "<ALPHANUM>","position": 4}]}
文档处理
文档冲突
概念
ES中一次性读取原始文档【比如使用IndexAPI】,同时修改以后重新索引整个文档,最后无论哪个文档被索引,都会被唯一地保存在ES中,其他的文档更改将失败,这样的方式问题不大
实际上Elasticsearch一般作为主关系型数据库的一个搜索数据库,将主关系型数据库的数据赋值到ES中并使其提供检索服务,比如存储了商城商品库存数量,每卖出一个商品,ES都会将库存相应地减少;但是在促销活动中,一秒可能会卖好几个商品,多个web线程并行地运行同一种商品的销售,同时读取了商品的库存,但是先完成的程序已经将库存耗光,后完成的程序并不知道这个情况,导致用户交易成功但实际上没有可以提供的商品,甚至可能导致先完成的库存数量扣减失效【比如使用下单时的商品库存而非结算时的商品库存,一般来说这种业务逻辑导致的问题都不算系统性问题,一般指瞬时速度太快,读到改的过程中其他变更已经发生,当前的改直接覆盖掉这期间发生的变更操作,用锁来控制拿到数据和更改的整个过程】,产生了数据变更发生丢失的问题
数据变更越频繁,读数据和更新数据的间隙越长,数据变更丢失的可能就越大
实际意思就是读数据和更新数据的时间间隔中发生数据频繁变更导致时间间隔中丢失数据更改的情况
确保更新时变更不丢失的方案
悲观并发控制
使用悲观锁来进行并发控制,悲观锁认为数据更改期间随时都会发生其他变更冲突,操作数据前需要拿到操作对象的锁,否则就进入阻塞等待状态,确保读到的数据不出错,修改的数据不发生变更丢失,但是这种方式效率低下,对相关数据操作无法并行进行
乐观并发控制
使用乐观锁进行并发控制会假定不会发生变更冲突,所有线程都可以并行地对数据进行操作,但是一旦通过一定手段发现读取数据到更改数据间隔期间数据发生变化,本次更新操作会失败,然后由程序来决定后续使用新数据来重新更新或者将相关情况报告给用户的后续行为
ES本身文档发生写操作的时候,新版本文档需要复制到复制分片中,这个过程也是异步和并发的,假如极短时间内发生两次写操作,后一次操作可能先到达复制分片,如果前一次操作直接将文档进行覆盖会导致后一次操作的变更丢失导致文档直接损坏【比如其他复制分片的顺序是正确的,导致复制分片上的文档数据不同】,ES使用version版本号来确保变更按照顺序正确地执行,早期的ES中如果修改请求的版本号不是当前当前的版本号,说明更改已经发生,更改请求会失败,现在新版本不支持使用version,会报错提示请求参数使用
if_seq_no和if_primary_term,但是可以都不写,这种情况仍然可以修改成功,但是请求中不携带版本号使用请求
http://127.0.0.1:1004/shopping/_create/1001【PUT】创建文档时响应结果中会显示文档版本信息请求体Json
xxxxxxxxxx{"title": "测试文档冲突"}响应结果
"_version"是文档数据的版本号,"_seq_no"和"_primary_term"是用于新版本版本号并发控制的判断依据
xxxxxxxxxx{"_index": "shopping","_type": "_doc","_id": "1001","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1}
使用请求
http://127.0.0.1:1004/shopping/_update/1001【POST】对文档数据进行一次更新请求体JSON
xxxxxxxxxx{"doc": {"title": "华为手机"}}响应体json
可以看到
version字段和_seq_no字段都变了xxxxxxxxxx{"_index": "shopping","_type": "_doc","_id": "1001","_version": 2,"result": "updated","_shards": {"total": 2,"successful": 2,"failed": 0},"_seq_no": 1,"_primary_term": 1}
使用请求
http://127.0.0.1:1004/shopping/_update/1001?version=2【POST】来指定版本号对文档数据进行更新,这种方式会直接报错,因为新版本不再支持指定version来使用乐观锁了,需要使用if_seq_no和if_primary_term【注意使用version或者if_seq_no和if_primary_term是针对更改需要使用乐观锁的情况,不加version字段也能更新,数据版本也会自增,但是请求数据没有加上文档的版本信息】请求体json
xxxxxxxxxx{"doc": {"title": "华为手机"}}响应体json
xxxxxxxxxx{"error": {"root_cause": [{"type": "action_request_validation_exception","reason": "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;"}],"type": "action_request_validation_exception","reason": "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;"},"status": 400}
使用
if_seq_no和if_primary_term做版本控制,发送请求http://127.0.0.1:1004/shopping/_update/1001?if_seq_no=1&if_primary_term=1【POST】请求体json
xxxxxxxxxx{"doc": {"title": "牛牛手机"}}响应体json
版本号和
_seq_no都变大了,注意当文档内容与原来一样的情况下,版本号和_seq_no不会发生变化xxxxxxxxxx{"_index": "shopping","_type": "_doc","_id": "1001","_version": 3,"result": "updated","_shards": {"total": 2,"successful": 2,"failed": 0},"_seq_no": 2,"_primary_term": 1}
外部系统版本控制
这种设置一般是用其他数据库作为主要数据库,用ES做数据检索,主数据库发生更改是被复制到ES,如果多个进程都对同一数据进行同步,可能就会遇到该并发更改丢失问题
此时主数据库中一般有用于版本控制的字段如
timestamp,在ES请求中通过增加version_type=external和指定version请求参数来使用该版本号,版本号的数值范围必须对应Java中的Long类型正整数外部系统版本控制中ES不是检查当前文档的版本号是否和更改请求中的版本号是否相同来判断更改是否生效,而是判断当前文档的版本号是否小于更改请求的版本号,如果小就执行更改并将更改请求的版本号作为新文档的版本号,即这种方式将版本控制问题交给程序和主数据库,自己只负责更新到达的最终版本数据
外部版本号不仅在索引和删除请求是可以指定,而且在创建新文档时也可以指定。
使用请求
http://127.0.0.1:1004/shopping/_doc/1001?version=1&version_type=external【POST】来使用外部系统的版本控制,注意这里是_doc,不再是上面的_update了请求体JSON
xxxxxxxxxx{"doc": {"title": "牛牛手机test1"}}响应体json
报错是因为请求中的版本号比ES中文档的版本号更低
xxxxxxxxxx{"error": {"root_cause": [{"type": "version_conflict_engine_exception","reason": "[1001]: version conflict, current version [10] is higher or equal to the one provided [1]","index_uuid": "Wy5pZ_2pTR2psd9aoq64fQ","shard": "0","index": "shopping"}],"type": "version_conflict_engine_exception","reason": "[1001]: version conflict, current version [10] is higher or equal to the one provided [1]","index_uuid": "Wy5pZ_2pTR2psd9aoq64fQ","shard": "0","index": "shopping"},"status": 409}将version改成10以后的响应体json
注意此时的请求version远大于ES中文档的version,更改后数据版本直接变成10
xxxxxxxxxx{"_index": "shopping","_type": "_doc","_id": "1001","_version": 10,"result": "updated","_shards": {"total": 2,"successful": 2,"failed": 0},"_seq_no": 4,"_primary_term": 1}
安装Kibana
免费开放用户界面,是ELK中的K,能让用户对ElasticSearch对数据进行可视化,此外还可以用于跟踪查询负载、理解请求如何流经整个应用
详细用法自己学习
安装
1️⃣:下载地址:
https://artifacts.elastic.co/downloads/kibana/kibana-7.8.0-windows-x86_64.zip,下载后解压2️⃣:修改
config/kibana.yml文件增加如下配置,默认配置下配置文件都是注释掉的🔎:8.x版本开始不再需要索引配置,启动会报错,注意
xxxxxxxxxx# 默认端口server.port5601# ES 服务器的地址elasticsearch.hosts"http://localhost:9200"# 索引名kibana.index".kibana"# 支持中文i18n.locale"zh-CN"3️⃣:双击执行
bin/kibana.bat文件,通过浏览器访问web可视化界面http://localhost:5601进去以后提示没有数据,但是实际用控制台查还是能查出数据
安装成功测试
kibana会自动在ES服务器中创建几个索引
点击控制台进入控制台,输入请求方式【全大写】和请求URI,点击运行能执行得到和使用PostMan一样请求的效果
控制台代码示例
xxxxxxxxxxGET shopping/_doc/1001响应效果
xxxxxxxxxx{"_index" : "shopping","_type" : "_doc","_id" : "1001","_version" : 10,"_seq_no" : 4,"_primary_term" : 1,"found" : true,"_source" : {"doc" : {"title" : "牛牛手机test1"}}}
ES集成其他框架
SpringData
为了简化ES操作,该框架的目的主要是为了简化数据库、非关系型数据库、索引库的访问操作,更方便快捷地访问数据,并支持 map-reduce 框架和云计算数据服务,SpringData可以极大地简化JPA写法,几乎可以在不写实现的情况下实现对数据的访问和操作,除了CRUD外还包括分页和排序等常用功能
框架简介
常用功能模块
Spring Data下有非常多的模块,以下只是常用的功能模块
Spring Data JDBC
Spring Data Redis
Spring Data ElasticSearch
Spring for Apache Hadoop
Spring Data ElasticSearch
简介
Spring Data Elasticsearch 基于 spring data API 简化 Elasticsearch 操作,将原始操作 Elasticsearch 的客户端 API 进行封装
版本:https://docs.spring.io/spring-data/elasticsearch/reference/elasticsearch/versions.html

创建Maven项目并集成Spring Data ElasticSearch
创建Maven项目并添加依赖关系
xxxxxxxxxx<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.atlisheng</groupId><artifactId>springdata-elasticsearch</artifactId><version>1.0-SNAPSHOT</version><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.6.RELEASE</version><relativePath/></parent><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-test</artifactId></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-test</artifactId></dependency></dependencies></project>配置
application.ymlxxxxxxxxxx#这里的配置是自己指定前缀以在自己的配置类中进行使用,默认配置项中没有该配置elasticsearchhost127.0.0.1port1003logginglevelcomatlishengesdebug编写主程序
xxxxxxxxxxpublic class SpringDataElasticSearchApplication {public static void main(String[] args) {SpringApplication.run(SpringDataElasticSearchApplication.class,args);}}编写对应索引的数据实体类
每个对象就是该索引下的一个文档
xxxxxxxxxx//为属性自动填充getter和setter方法//无参构造//全参构造//重写实体类的toString方法public class Product {private Long id;//商品唯一标识private String title;//商品名称private String category;//分类名称private Double price;//商品价格private String images;//图片地址}编写配置类
ElasticsearchRestTemplate是spring-data-elasticsearch项目中的一个类,和其他 spring 项目中的template类似, 在新版的spring-data-elasticsearch中,ElasticsearchRestTemplate代替了原来的ElasticsearchTemplate,原因是ElasticsearchTemplate基于TransportClient,TransportClient即将在 8.x 以后的版本中移除。所以推荐使用ElasticsearchRestTemplate,ElasticsearchRestTemplate基 于RestHighLevelClient客 户 端 的 。 需要自定义配置类 , 继承AbstractElasticsearchConfiguration,并实现elasticsearchClient()抽象方法来创建RestHighLevelClient对象并向容器进行注入xxxxxxxxxximport lombok.Data;import org.apache.http.HttpHost;import org.elasticsearch.client.RestClient;import org.elasticsearch.client.RestClientBuilder;import org.elasticsearch.client.RestHighLevelClient;import org.springframework.boot.context.properties.ConfigurationProperties;import org.springframework.context.annotation.Configuration;import org.springframework.data.elasticsearch.config.AbstractElasticsearchConfiguration;/*** @author Earl* @version 1.0.0* @描述 删除文档可以使用该配置类,该restHighLevelClient应该是容器中ElasticsearchRestTemplate的子实现类,* 明确调用删除索引时需要使用该对象,猜测日常操作如创建索引或者对文档操作都会使用到该对象,因为需要获取服务器集群的地址* 只需要向单节点一样使用集群即可* @创建日期 2024/05/02* @since 1.0.0*/(prefix = "elasticsearch")public class ElasticsearchConfig extends AbstractElasticsearchConfiguration {private String host ;private Integer port ;public RestHighLevelClient elasticsearchClient() {RestClientBuilder builder = RestClient.builder(new HttpHost(host, port));RestHighLevelClient restHighLevelClient = new RestHighLevelClient(builder);return restHighLevelClient;}}编写Dao用户操作数据对象访问数据库
xxxxxxxxxximport com.atlisheng.es.entity.Product;import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;import org.springframework.stereotype.Repository;public interface ProductDao extends ElasticsearchRepository<Product,Long> {}索引操作API
创建索引和删除索引
xxxxxxxxxx(SpringRunner.class)public class SpringDataESIndexTest {private ElasticsearchRestTemplate elasticsearchRestTemplate;/*** @描述 测试创建索引并增加映射配置,系统初始化会自动检查ES服务器中是否有对应名字的索引,* 没有会自动创建关联实体类product的对应索引,所以这个方法其实是没必要的,只要系统初始化就会自动检查* 注意实体类对应的索引名字是系统初始化检查服务器索引是否存在的唯一判据,即使指定了分片数量和副本数量,索引名在* 原服务器已经存在的情况下,即便主分片数量或者复制分片不同也不会重新创建索引,只有当索引名不存在的情况下才会创建* 对应实体类的指定索引* @author Earl* @version 1.0.0* @创建日期 2024/05/02* @since 1.0.0*/public void createIndex(){System.out.println("创建索引");}/*** @描述 删除索引通过ElasticsearchRestTemplate的deleteIndex(Product.class)方法通过指定对应索引的实体类,* 删除成功返回true,删除失败返回false* 来删* @author Earl* @version 1.0.0* @创建日期 2024/05/02* @since 1.0.0*/public void deleteIndex(){boolean flg = elasticsearchRestTemplate.deleteIndex(Product.class);System.out.println("删除索引 = " + flg);}}【索引自动创建效果】

文档操作API
根据id对指定文档进行操作
xxxxxxxxxximport com.atlisheng.es.dao.ProductDao;import com.atlisheng.es.entity.Product;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.data.domain.Page;import org.springframework.data.domain.PageRequest;import org.springframework.data.domain.Sort;import org.springframework.test.context.junit4.SpringRunner;import java.util.ArrayList;import java.util.List;/*** @author Earl* @version 1.0.0* @描述 根据id对指定文档进行操作* @创建日期 2024/05/02* @since 1.0.0*/(SpringRunner.class)public class SpringDataESDocumentTest {private ProductDao productDao;/*** productDao.save(product);向ES集群中新增文档数据,* 意味着从数据库取出的数据可以通过SpringData ES直接用save存入ES服务器*/public void save(){Product product = new Product();product.setId(2L);product.setTitle("华为手机");product.setCategory("手机");product.setPrice(2999.0);product.setImages("http://www.atguigu/hw.jpg");productDao.save(product);}/*** productDao.save(product) 传入对象来修改对应实体类的索引下的id的文档数据,没有对应的id的文档就新建文档数据,* 有对应id的文档数据就修改文档数据*/public void update(){Product product = new Product();product.setId(1L);product.setTitle("小米 2 手机");product.setCategory("手机");product.setPrice(9999.0);product.setImages("http://www.atguigu/xm.jpg");productDao.save(product);}/*** productDao.findById(1L).get() 根据id和实体类查询文档数据* */public void findById(){Product product = productDao.findById(1L).get();System.out.println(product);}/*** productDao.findAll() 查询实体类对应索引下的所有文档数据* */public void findAll(){Iterable<Product> products = productDao.findAll();for (Product product : products) {System.out.println(product);}}/*** productDao.delete(product) 根据实体类对象删除文档数据* */public void delete(){Product product = new Product();product.setId(1L);productDao.delete(product);}/*** productDao.saveAll(productList) 通过实体类集合批量保存或者修改文档数据* */public void saveAll(){List<Product> productList = new ArrayList<>();for (int i = 0; i < 10; i++) {Product product = new Product();product.setId(Long.valueOf(i));product.setTitle("["+i+"]小米手机");product.setCategory("手机");product.setPrice(1999.0+i);product.setImages("http://www.atguigu/xm.jpg");productList.add(product);}productDao.saveAll(productList);}/*** productDao.findAll(pageRequest) 分页排序查询文档数据,传参pageRequest对象* 返回Page<Product>对象,通过该对象的getContent()方法可以获取文档数据列表** PageRequest.of(currentPage, pageSize,sort) 传参当前页码、每页记录数和排序策略封装分页排序查询参数返回pageRequest对象* sort=Sort.by(Sort.Direction.DESC,"id")中分别封装排序方式,排序的id,sort是org.springframework.data.domain.Sort* PageRequest也是org.springframework.data.domain包下的* */public void findByPageable(){//设置排序(排序方式,正序还是倒序,排序的 id)Sort sort = Sort.by(Sort.Direction.DESC,"id");int currentPage=0;//当前页,第一页从 0 开始, 1 表示第二页int pageSize = 5;//每页显示多少条//设置查询分页PageRequest pageRequest = PageRequest.of(currentPage, pageSize,sort);//分页查询Page<Product> productPage = productDao.findAll(pageRequest);for (Product Product : productPage.getContent()) {System.out.println(Product);}}}【批量保存文档数据效果】

使用检索词条对文档进行搜索
xxxxxxxxxximport com.atlisheng.es.dao.ProductDao;import com.atlisheng.es.entity.Product;import org.elasticsearch.index.query.QueryBuilders;import org.elasticsearch.index.query.TermQueryBuilder;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.data.domain.PageRequest;import org.springframework.test.context.junit4.SpringRunner;/*** @author Earl* @version 1.0.0* @描述 通过查询条件对文档进行检索* @创建日期 2024/05/02* @since 1.0.0*/(SpringRunner.class)public class SpringDataESSearchTest {private ProductDao productDao;/*** term 查询* search(termQueryBuilder) 调用搜索方法,参数查询构建器对象* 用QueryBuilders.termQuery("title", "小米")来构建查询条件,分别封装查询字段和检索词条* 用productDao.search(termQueryBuilder)来查询满足检索条件的文档数据* 返回Iterable<Product>,可以直接遍历*/public void termQuery(){TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "小米");Iterable<Product> products = productDao.search(termQueryBuilder);for (Product product : products) {System.out.println(product);}}/*** term 查询加分页* 用QueryBuilders.termQuery("title", "小米")来构建查询条件,分别封装查询字段和检索词条* 用pageRequest来封装分页参数* 用productDao.search(termQueryBuilder,pageRequest)来分页查询满足检索条件的文档数据* 返回Iterable<Product>,可以直接遍历*/public void termQueryByPage(){int currentPage= 0 ;int pageSize = 5;//设置查询分页PageRequest pageRequest = PageRequest.of(currentPage, pageSize);TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "小米");Iterable<Product> products = productDao.search(termQueryBuilder,pageRequest);for (Product product : products) {System.out.println(product);}}}
SparkStreaming
为了将数据处理的结果放在ES中,这是和大数据相关的,写的东西看不懂,后面学大数据相关的内容再学习吧,Flink也是大数据的,TODO
Flink
TODO
Elasticsearch优化
硬件选择
Elasticsearch的基础是Lucene,所有的索引和文档数据都存储在本地,路径可以在
../config/elasticsearch.yml中进行配置xxxxxxxxxx# Path to directory where to store the data (separate multiple locations by comma):##path.data: /path/to/data## Path to log files:##path.logs: /path/to/logsElasticSearch重度使用磁盘,磁盘能处理的吞吐量越大,节点越稳定,以下列举磁盘I/O的优化技巧
使用SSD固态硬盘替代机械硬盘,ES是一种密集使用磁盘的应用,在段合并的时候会频繁操作磁盘,所以对磁盘要求较高,当磁盘速度提升之后,集群的整体性能会大幅度提高
使用RAID0条带化RAID能提高磁盘I/O,提高性能的原理是将连续的数据分散到多个磁盘中存取,数据请求可以被多个磁盘并行地执行,代价是一块硬盘故障时整个磁盘就故障,不要使用镜像或者奇偶校验 RAID 因为副本已经提供了这个功能
使用多块硬盘,并配置Elasticsearch通过多个
path.data目录配置把数据条带化分配在多块硬盘上不要使用NFS、SMB/CIFS等远程挂载的存储,这会引入延迟
分片策略
合理设置分片数
分片数不能无限地分配,主要有以下原因
一个分片的底层就是一个Lucene索引,会消耗一定文件句柄、内存和CPU运转
每个搜索请求都需要命中索引中的一个分片,当每个分片都处于不同的节点能够较好地分散查询压力,如果分片太多,多个查询都命中同一个节点,在同一个节点上竞争使用相同的资源就很糟糕了
用于计算相关度的词项统计信息是基于分片的。如果有许多分片,每一个都只有很少的数据会导致很低的相关度
分片数量规定好以后无法进行修改
设置分片数量的原则
每个分片占用的硬盘容量不要超过JVM的最大堆空间设置【一般是32G】,如索引总容量500G左右,则该索引的分片数量设置为大于16个
同时还要考虑节点数量,一般设置分片数不超过节点数的3倍,如果分片数大大超过节点数,很可能导致一个节点上存在多个分片【多个复制分片位于同一个节点上?】,一旦该节点故障,同样可能导致数据丢失,主分片、副本和节点数之间的配置一般参考以下关系:节点数>=主分片书*(副本数+1)
推迟分片分配
当节点瞬时中断发生后,ES会自动再平衡可用分片【暂时认为是自动重新分配索引分片】,这种再平衡分片的过程会带来极大的开销,默认情况下,集群会等待一分钟来观察瞬时中断节点是否会重新加入,如果此期间节点重新加入,不触发新的分片分配,重新加入的瞬时中间节点保持现有的分片数
修改参数
delayed_timeout可以延长从瞬时中断到触发新的分片分配的时间,可以全局配置也可以在索引级别进行修改发送请求
/all/_settings【PUT】修改分片再分配时间间隔为5分钟,请求体JSON如下xxxxxxxxxx{"settings": {"index.unassigned.node_left.delayed_timeout": "5m"}}
路由选择
不带routing查询
由于查询时不知道目标数据所在的具体分片,即无法通过路由公式计算出来,查询请求到达协调节点后,协调节点将查询请求分发到每个分片上,每个分片都处理查询请求并将查询结果响应给协调节点
协调节点搜集每个分片上的查询结果,对查询结果进行排序,并将聚合的查询结果响应给客户
带路由查询
查询文档时,ElasticSearch根据路由公式shard = hash(routing) % number_of_primary_shards计算出文档所在的主分片,路由routing的默认值是文档的id,也可以采用自定义值如用户id
查询时可以直接根据routing信息定位到某个分片,不再需要查询所有分片
讲的太垃圾,根本没说如何设置routing为自定义路由参数,如何根据自定义的routing参数分配数据到指定分片上,并由此根据数据分片特点以特定的自定义routing参数让一次查询请求集中在一个分片上来提升查询效率
写入速度优化
ES 的默认配置,是综合了数据可靠性、写入速度、搜索实时性等因素。实际使用时,我们需要根据公司要求,进行偏向性的优化,针对于搜索性能要求不高,但是对写入要求较高的场景,我们需要尽可能的选择恰当写优化策略
优化策略
增大Translog日志的刷新时间,来降低磁盘的每秒输入输出Iops、写锁操作Writeblock【压根就没讲这玩意】
增加索引的Refresh间隔,减少分片merge的次数【即小分片合并成一个大分片的操作】
调整Bulk批量处理的线程池和队列,批量处理数据越多,效率越快【非常地敷衍】
优化Lucene层面的索引建立过程,降低CPU和I/O的消耗
批量数据提交
大量写任务可以使用Bulk来进行批量写入,默认情况下Bulk的默认设置批量处理单次提交的数据量不超过100MB,数据条数根据文档的大小和服务器性能确定,实际的单次提交数据量应该以5-15MB的步长一次增加,直到Bulk的批量写入性能没有提升时以该数据量作为单次批量处理提交的数据量大小
段合并会频繁使用磁盘,磁盘的读写速度提升后,集群的整体性能也会大幅提升
合理使用合并
新数据写入索引就会创建新的段,段的数量越多,消耗的文件句柄数和CPU就越多,查询效率就会下降
Lucene段合并的计算量非常庞大,会消耗大量的I/O,ES采用较保守的策略,让后台定期进行段合并
减少refresh的次数
Lucene在新增数据时,默认情况下索引的 refresh_interval 为1秒,即Lucene将待写入的数据先写入到内存中,默认1秒触发一次refresh,将内存中的数据刷新到操作系统的文件缓存系统中,如果对搜索的时效性要求不高,即新增数据不需要被近实时查询,将Refresh周期延长,例如 30 秒,减少refresh操作,但是这样同时会增加更多的Heap内存消耗
加大Flush设置
Flush的目的是将文件缓存系统中的段持久化到硬盘,Translog数据量到达512MB或者30min时就会触发一次Flush
index.translog.flush_threshold_size参数的默认值是 512MB,我们进行修改增大该参数值,但是同时增大该参数值意味着文件缓存系统需要更大的空间来存储更多的数据
减少副本的数量
每个副本在新增数据的过程中都会执行分析索引和合并的过程,副本数量也会严重影响写索引的效率
写索引时,写入的数据同步到副本节点,副本节点越多,写索引的效率就越低
进行大批量写入操作时,可以先禁止副本复制,设 置
index.number_of_replicas: 0关闭副本,写入完成后在将副本恢复成可以复制的状态
内存设置
背景
ES默认安装后设置的内存是1GB,对于任何一个现实业务来说该内存设置都太小了,通过解压安装的ES在ES的安装文件中包含一个名为
config/jvm.option的文件,在其中通过命令-Xms1g和-Xmx1g来设置ES的堆内存大小,Xms表示堆内存的初始大小,Xmx表示可分配的最大内存,默认都是1GB确保初始堆内存大小Xmx和可分配的最大内存大小Xms是相同的,目的是确保Java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源,可以减轻伸缩堆大小带来的压力
ES堆内存分配的原则
ES的堆内存不是分配的越多越好,要满足以下两个原则
堆内存不要超过物理内存的50%,Lucene的设计目的是将底层操作系统的数据缓存在内存中,Lucene中的段分别存储在单个文件中,这些段文件不会发生变化,缓存起来很方便,操作系统会将这些段文件缓存起来,一遍实现更快的访问,如果将堆内存设置过大,Lucene可以使用来进行段文件缓存的内存就会减少,严重降低Lucene的全文本查询性能,而且操作系统文件缓存空间太小会导致新增的数据频繁落盘,增加系统CPU和I/O资源的消耗
堆内存大小最好不要超过32GB,Java中所有对象都分配在堆上,由一个
Klass Pointer指针指向其类元数据,该指针子啊64位操作系统上为64位,64位操作系统上可以操作264字节的内存【远大于32G,这个可寻址的空间大的可怕,是4*232GB】;而在32位操作系统上为32位,最大寻址空间为232【4GB】,使用64位指针意味着指针本身大了浪费内存,同时更大的指针在主内存和缓存器(例如 LLC, L1 等)之间移动数据的时候,会占用更多的带宽【但是我实在不明白寻址空间为4GB为什么要分配32G的堆内存空间,而且也没说选择和操作系统位数之间的关系,难道我使用64位操作系统和使用32位操作系统分配的堆内存是相同的吗?讲的太烂了】,注意这里说的是每个节点的JVM堆内存不要超过32G,此前分片策略说的是每个节点上的每个分片占用的硬盘容量不要超过对应节点的堆内存空间32G,这个32G是人为一般设置,默认设置是1G,太小了一般的配置策略是采用31G配置,即修改默认配置为
-Xms31g和-Xmx31g
重要参数配置
cluster.name参数值:
cluster.name: elasticsearch默认值:
elasticsearch作用域: ES集群
配置说明:配置ES的集群名称,默认名称为
elasticsearch,ES会自动发现同一网段下集群名称相同的节点配置实例:
xxxxxxxxxxcluster.nameelasticsearch
node.name参数值:
node.name: node-1默认值:
作用域: ES节点
配置说明:配置集群中的节点名,同一个集群中节点名不能重复,节点名一旦设置就不能再改变,也可以通过设置变量的方式设置成节点所在的主机名称,如
node.name: ${HOSTNAME}配置实例:
xxxxxxxxxxnode.namenode-1
node.master参数值:
node.master: true默认值:
true作用域: ES集群
配置说明:指定当前节点是否有资格被选举称为master节点,设置为true表示该节点有资格成为master节点,是否成为master节点,需要通过选举产生
配置实例:
xxxxxxxxxxnode.mastertrue
node.data参数值:
node.data: true默认值:
true配置说明:指定当前节点是否存储索引数据,也即当前节点是否data节点,数据的增删改查都是在data节点完成的
配置实例:
xxxxxxxxxxnode.datatrue
index.number_of_shards参数值:
index.number_of_shards: 1默认值:
1配置说明:设置索引主分片个数,默认是一个主分片,也可以在创建索引时来设置索引的主分片个数,具体值要根据数据量的大小来确定,数据量不大的情况下设置为1时的效率最高
配置实例:
xxxxxxxxxxindex.number_of_shards1
index.number_of_replicas参数值:
index.number_of_replicas: 1默认值:
1配置说明:设置默认的索引副本个数,默认为1个副本,副本数越多,集群的可用性越高,但是写索引时需要同步的数据越多
配置实例:
xxxxxxxxxxindex.number_of_replicas1
transport.tcp.compress参数值:
transport.tcp.compress: true默认值:
false配置说明:设置在节点间传输数据时是否对数据进行压缩,默认为false,不进行压缩
配置实例:
xxxxxxxxxxtransport.tcp.compresstrue
discovery.zen.minimum_master_nodes参数值:
discovery.zen.minimum_master_nodes: 1默认值:
1配置说明:设置在选举master节点时需要参与的最小的候选主节点数,默认为1,
🔎:如果使用默认值1,当网络不稳定时可能发生脑裂现象,即由于网络故障,master节点并没有宕机,但是集群选举出了另一个master节点,产生两个master节点的情况
🔎:合理的数量为(master_eligible_nodes/2)+1,其中
master_eligible_nodes表示集群中的候选主节点数
配置实例:
xxxxxxxxxxdiscovery.zen.minimum_master_nodes1
discovery.zen.ping.timeout参数值:
discovery.zen.ping.timeout: 3s默认值:
3s配置说明:设置集群中自动发现其他节点时Ping连接的超时时间,默认为3秒,较差的网络该值需要设置得大一些,防止因误判节点的存活状态从而导致分片的转移
配置实例:
xxxxxxxxxxdiscovery.zen.ping.timeout3s
ES项目知识
这是在项目中学习到的ES知识,明显比尚硅谷的这个ES课程讲的好太多了,后续复习的时候整理在一起,这里只是先存在这里方便查询
ES常用WEB API
节点信息相关
【GET】
http://192.168.56.10:9200/请求体:无
功能:测试ES的安装运行是否正常
响应内容:
xxxxxxxxxx{"name": "ecb880026b14","cluster_name": "elasticsearch","cluster_uuid": "zxPeJYB9SraGL0p_R4dT0g","version": {"number": "7.4.2","build_flavor": "default","build_type": "docker","build_hash": "2f90bbf7b93631e52bafb59b3b049cb44ec25e96","build_date": "2019-10-28T20:40:44.881551Z","build_snapshot": false,"lucene_version": "8.2.0","minimum_wire_compatibility_version": "6.8.0","minimum_index_compatibility_version": "6.0.0-beta1"},"tagline": "You Know, for Search"}
【GET】
http://192.168.56.10/_cat/nodes请求体:无
功能:查看当前ES集群的节点信息
响应内容:
响应当前集群下的所有节点信息,当前单节点模式启动,所以只有一个节点,这个最后的
ecb880026b14就是上面URL响应结果中的节点名称星号表示当前节点是一个主节点
xxxxxxxxxx127.0.0.1 12 93 0 0.05 0.05 0.05 dilm * ecb880026b14补充说明:_cat下应该有很多的相关API,单纯的
http://192.168.56.10/_cat响应结果如下,返回_cat后能跟所有子urixxxxxxxxxx=^.^=/_cat/allocation/_cat/shards/_cat/shards/{index}/_cat/master/_cat/nodes/_cat/tasks/_cat/indices/_cat/indices/{index}/_cat/segments/_cat/segments/{index}/_cat/count/_cat/count/{index}/_cat/recovery/_cat/recovery/{index}/_cat/health/_cat/pending_tasks/_cat/aliases/_cat/aliases/{alias}/_cat/thread_pool/_cat/thread_pool/{thread_pools}/_cat/plugins/_cat/fielddata/_cat/fielddata/{fields}/_cat/nodeattrs/_cat/repositories/_cat/snapshots/{repository}/_cat/templates
【GET】
http://192.168.56.10:9200/_cat/health请求体:无
功能:查看ES集群的所有节点健康信息
响应内容:
green表示当前节点健康,后面的数字是集群分片信息
xxxxxxxxxx1715958975 15:16:15 elasticsearch green 1 1 3 3 0 0 0 0 - 100.0%
【GET】
http://192.168.56.10:9200/_cat/master请求体:无
功能:查看主节点信息
响应内容:
hcAGB9fFT0uRZ2xR36VZlA是主节点的唯一编号,ecb880026b14是主节点的名称,127.0.0.1是主节点地址
xxxxxxxxxxhcAGB9fFT0uRZ2xR36VZlA 127.0.0.1 127.0.0.1 ecb880026b14
索引文档CURD相关
【GET】
http://192.168.56.10:9200/_cat/indices请求体:无
功能:查看ES集群中的所有索引,相当于查看查看mysql中的所有数据库
响应内容:
目前还没有向ES中添加索引,这些索引都是kibana相关的一些配置信息,由kibana在ES中创建的
xxxxxxxxxxgreen open .kibana_task_manager_1 Pk143YyKQci-HaAIS4oQ8w 1 0 2 0 38.2kb 38.2kbgreen open .apm-agent-configuration btC4ECICSQStzecqlpLb7Q 1 0 0 0 283b 283bgreen open .kibana_1 hckOIIBjTJesypzK4lrXhQ 1 0 8 0 28.6kb 28.6kb
【PUT】
http://192.168.56.10:9200/customer/external/1请求体:
请求体json就是文档数据
xxxxxxxxxx{"name": "John Doe"}功能:向ES服务器索引一个文档,customer是文档的索引,external是文档类型,值得注意的是在ES8中已经废除了文档类型的概念,可以直接以【PUT】
http://192.168.56.10:9200/customer/1来索引文档,PUT带id的索引文档操作,PUT请求方式的索引文档必须携带id,不携带id会直接报错,多次执行是更新操作,文档数据的版本号会累加,一般都将PUT方式的索引文档用来做更新操作响应内容:
响应数据中以
_开头的称为元数据,反应一个文档的基本信息,_index表示当前文案数据在哪一个索引下,_type表示当前文档所在的类型,_id是文档数据对应的id,_version是文档数据的版本,result是本次操作的结果,_shards是分片的相关信息
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1}补充说明:
再次发送该请求响应内容中的
result会变成updated,且版本号自动发生了累加xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 2,"result": "updated","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 1,"_primary_term": 1}这种方式是全量更新,即请求体文档数据直接覆盖原文档数据内容
【POST】
http://192.168.56.10/customer/external请求体:
请求体json就是文档数据
xxxxxxxxxx{"name": "John Doe"}功能:像ES服务器索引一个文档,不指定id的情况下会自动生成唯一id,多次放松请求,每次响应都是created操作,且都会响应不同的唯一id,版本号不发生变化;携带id,第一次请求是created操作,此后多次发送相同请求,会显示是updated操作,且文旦数据的id唯一,版本号会相应累加;即带id和PUT方式的功能是完全相同的,不带id自动生成id并且每次请求都是全新的新增文档操作
响应内容:
【不携带id】
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1ll4io8B6tdhia0R4XMN","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 2,"_primary_term": 1}【不携带id多次发送效果】
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "11l5io8B6tdhia0Rn3Mj","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 3,"_primary_term": 1}【携带id】
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "3","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 5,"_primary_term": 1}【携带id多次发送效果】
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "3","_version": 2,"result": "updated","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 6,"_primary_term": 1}补充说明:
这种方式是全量更新,即请求体文档数据直接覆盖原文档数据内容
【GET】
http://192.168.56.10:9200/customer/external/1请求体:无
功能:通过指定索引分类和id检索指定文档数据
响应内容:
_seq_no和_primary_term是做乐观锁操作的,数据发生改动,序列号_seq_no就会往上加,分片发生变化如集群重启或者主分片重新选举,_primary_term也会发生相应的变化;老版本做乐观锁用的是version,新版本禁止使用version而在请求参数中带这两个参数来替代了;不过对于版本控制又外部逻辑处理的时候还是可以使用versionfound表示对应的文档数据被找到_source表示文档数据的具体内容
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 3,"_seq_no": 4,"_primary_term": 1,"found": true,"_source": {"name": "John Doe"}}
【PUT】
http://192.168.56.10:9200/customer/external/1?if_seq_no=4&if_primary_term=1请求体
xxxxxxxxxx{"name": "1"}功能:当文档数据的
_seq_no和_primary_term和请求参数的对应参数值相同时执行更新操作,即使用乐观锁来做文档数据的并发操作控制响应内容:
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 4,"result": "updated","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 8,"_primary_term": 1}补充说明:
注意文档索引过程中使用了类型,更新文档时的URI中也必须使用类型,否则请求会直接报错
【POST】
http://192.168.56.10:9200/customer/external/1/_update请求体
xxxxxxxxxx{"doc":{"name": "John"}}功能:根据文档数据的索引、类型、文档id和文档内容对文档数据进行更新,如果文档数据和ES服务器中的文档数据内容相同,多次操作ES服务器中的数据不会发生任何变化,连数据的版本号都不会发生变化,在响应内容的result为noop,表示什么都不做,然而不带
_update的更新操作不会检查原文档数据是否和需要更新后的文档数据是否一致;同时注意使用_update进行更新,更新内容要放在请求体的doc属性中响应内容:
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 6,"result": "updated","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 10,"_primary_term": 1}【多次操作单文档数据不变的响应】
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 6,"result": "noop","_shards": {"total": 0,"successful": 0,"failed": 0},"_seq_no": 10,"_primary_term": 1}补充说明:
带
_update的更新请求只能是POST请求方式,不能使用PUT请求方式,且带_update的POST请求是局部更新,即文档数据不会直接全部覆盖,有对应属性的数据相应修改,没有对应的属性就保留原文档数据,新增没有的属性和相应的数据;但是注意不带_update的上述两种PUT和POST方式的更新都是全量更新,即直接用请求体的数据直接将原文档数据全部直接覆盖
【DELETE】
http://192.168.56.10:9200/customer/external/1请求体:无
功能:根据索引、类型和文档id删除指定文档数据
响应内容:
xxxxxxxxxx{"_index": "customer","_type": "external","_id": "1","_version": 10,"result": "deleted","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 14,"_primary_term": 1}
【DELETE】
http://192.168.56.10:9200/customer请求体:无
功能:根据索引名称删除索引和索引下的所有数据
响应内容:
xxxxxxxxxx{"acknowledged": true{}}补充说明:
ES中没有提供删除类型的操作,删除索引会自动删除所有类型,清空一个文档下的所有文档数据也会同时删除掉其所属的类型,实际上基于用法的感知上没啥区别,因为向某个类型下添加文档数据也需要知道对应类型的名字
BULK批量相关
【POST】
http://192.168.56.10:9200/customer/external/_bulk请求体
每两行是一个整体,请求体语法格式在补充说明部分给出,index表示这是批量新增操作,
{"_id":"1"}是在URI中已知索引和类型的情况下指定当前数据的id,实际上完整的内容为{ "index": { "_index": "customer", "_type": "external", "_id": "1" }},第二行是完整的文档数据请求体的数据类型还是选择json,虽然PostMan会标红
注意使用PostMan发送该请求,后一行后面要加一个回车才行,使用kibana不需要加回车
xxxxxxxxxx{"index":{"_id":"1"}}{"name": "John Doe" }{"index":{"_id":"2"}}{"name": "Jane Doe" }功能:批量操作数据
响应内容:
"took": 134表示该批量操作耗时134毫秒"errors": false表示过程中没有发生任何错误items保存批量处理中每个处理的对应响应结果,index表示本次操作是一个保存操作,接着是三个元信息,版本号、操作结果、分片信息、版本号相关信息、"status": 201是该操作的状态码,表示刚新建完成
xxxxxxxxxx{"took": 134,"errors": false,"items": [{"index": {"_index": "customer","_type": "external","_id": "1","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1,"status": 201}},{"index": {"_index": "customer","_type": "external","_id": "2","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 1,"_primary_term": 1,"status": 201}}]}补充说明:
批量操作的每一条记录都是独立的,上一条文档数据的操作失败不会影响下一条数据的操作
请求体数据的语法格式
action是操作类型,
metadata是一个文档数据的原数据信息如索引、类型和id第二行紧跟完整的文档数据
随后循环添加要批量执行的其他操作
xxxxxxxxxx{ action: { metadata }}\n{ request body }\n{ action: { metadata }}\n{ request body }\n【action的所有类型,偶数行是对应的文档数据,删除操作不需要文档数据】
xxxxxxxxxx{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}{ "title": "My first blog post" }{ "index": { "_index": "website", "_type": "blog" }}{ "title": "My second blog post" }{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} }{ "doc" : {"title" : "My updated blog post"} }在uri中指定了索引和类型就是针对具体索引及类型下的操作,没有指定就是针对整个ES的操作,需要在请求体中指定索引和类型
ES官方提供的批量处理测试数据,原网址数据已经找不到了,这里从谷粒商城评论区找的移动到自己的gitee上的https://gitee.com/earl-Li/ES-bulk-testdata/blob/master/%E6%95%B0%E6%8D%AE,注意这个数据的元数据不含索引和类型,必须要自己在URI中进行指定,否则执行报错,这里的URI使用【POST】
http://192.168.56.10:9200/bank/account/_bulk,使用官方的批量操作测试数据进行批量操作API的测试
批量删除示例
【Kibana命令示例】
xxxxxxxxxxPOST mall_product/_bulk{"delete": {"_index": "mall_product","_id": 13}}{"delete": {"_index": "mall_product","_id": 14}}{"delete": {"_index": "mall_product","_id": 15}}{"delete": {"_index": "mall_product","_id": 16}}【响应结果】
xxxxxxxxxx{"took" : 27,"errors" : false,"items" : [{"delete" : {"_index" : "mall_product","_type" : "_doc","_id" : "13","_version" : 7,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 40,"_primary_term" : 1,"status" : 200}},{"delete" : {"_index" : "mall_product","_type" : "_doc","_id" : "14","_version" : 7,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 41,"_primary_term" : 1,"status" : 200}},{"delete" : {"_index" : "mall_product","_type" : "_doc","_id" : "15","_version" : 7,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 42,"_primary_term" : 1,"status" : 200}},{"delete" : {"_index" : "mall_product","_type" : "_doc","_id" : "16","_version" : 7,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 43,"_primary_term" : 1,"status" : 200}}]}
检索相关
ES的检索支持两种方式:
第一种方式是在uri中直接添加请求参数
第二种方式是在请求体中添加请求参数
【GET】
http://192.168.56.10:9200/bank/_search?q=*&sort=account_number:asc请求体:无【使用uri中直接添加请求参数的方式,所以请求体无】
功能:查询索引bank下的所有数据并将查询结果按照字段
account_number进行升序排列响应内容:
took- Elasticsearch执行搜索的时间( 毫秒)time_out- 告诉我们搜索是否超时_shards- 告诉我们多少个分片被搜索了, 以及统计了成功/失败的搜索分片hits- 搜索结果hits.total- 搜索结果整体信息,value是有多少条记录被搜索到hits.hits- 实际的搜索结果数组( 默认为前 10 的文档),包含文档数据的元数据信息,当前文档的得分,_source原文档数据,sort是排序,从0开始;ES一次只会最多返回前10条数据,不会一次性返回所有数据,sort- 结果的排序 key( 键) ( 没有则按 score 排序)score和max_score–相关性得分和最高得分(全文检索用)【因为本次查询就是查所有,不涉及模糊匹配等过程,所以没有评分数据】
xxxxxxxxxx{"took" : 72,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "bank","_type" : "account","_id" : "0","_score" : null,"_source" : {"account_number" : 0,"balance" : 16623,"firstname" : "Bradshaw","lastname" : "Mckenzie","age" : 29,"gender" : "F","address" : "244 Columbus Place","employer" : "Euron","email" : "bradshawmckenzie@euron.com","city" : "Hobucken","state" : "CO"},"sort" : [0]},{"_index" : "bank","_type" : "account","_id" : "9","_score" : null,"_source" : {"account_number" : 9,"balance" : 24776,"firstname" : "Opal","lastname" : "Meadows","age" : 39,"gender" : "M","address" : "963 Neptune Avenue","employer" : "Cedward","email" : "opalmeadows@cedward.com","city" : "Olney","state" : "OH"},"sort" : [9]}]}}补充说明:
请求参数中
q=*表示查询所有,sort=account_number:asc表示查询数据按照字段account_number的值升序排列
【GET】
http://192.168.56.10:9200/bank/_search请求体:
query表示查询条件,match_all是进行精确匹配,匹配全部内容后面写写一个空的大括号sort表示设置排序规则,按照account_number进行升序排列;排序规则是一个数组,可以多个排序规则组合使用,如第二个查询请求体,对应的排序规则是先按照account_number字段升序,在account_number相等的情况下再按照balance字段降序排序规则可以简写为
字段: 排序方式的方式,如第三个查询请求体所示可以通过
from和size指定当前页第几位开始的文档数据和当前页的总记录条数
xxxxxxxxxx#第一个查询请求体{"query": {"match_all": {}},"sort": [{"account_number": {"order": "asc"}}]}#第二个查询请求体{"query": {"match_all": {}},"sort": [{"account_number": {"order": "asc"},"balance": {"order": "desc"}}]}#第三个查询请求体{"query": {"match_all": {}},"sort": [{"account_number": "asc"},{"balance": "desc"}]}#第四个查询请求体{"query": {"match_all": {}},"sort": [{"account_number": "asc"}],"from": 10,"size": 10}功能:查询索引bank下的所有数据并将查询结果按照字段
account_number进行升序排列响应内容:
xxxxxxxxxx{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "bank","_type" : "account","_id" : "0","_score" : null,"_source" : {"account_number" : 0,"balance" : 16623,"firstname" : "Bradshaw","lastname" : "Mckenzie","age" : 29,"gender" : "F","address" : "244 Columbus Place","employer" : "Euron","email" : "bradshawmckenzie@euron.com","city" : "Hobucken","state" : "CO"},"sort" : [0]},{"_index" : "bank","_type" : "account","_id" : "9","_score" : null,"_source" : {"account_number" : 9,"balance" : 24776,"firstname" : "Opal","lastname" : "Meadows","age" : 39,"gender" : "M","address" : "963 Neptune Avenue","employer" : "Cedward","email" : "opalmeadows@cedward.com","city" : "Olney","state" : "OH"},"sort" : [9]}]}}补充说明:
这种将查询条件封装到请求体中的方式被ES称为Query DSL【领域对象语言】,ES官方文档中专门对Query DSL开了一个章节进行介绍,也是ES中最常用的查询方式,即请求体中封装查询参数的部分称为Query DSL
Query DSL的语法
ES提供一个可以被执行查询的JSON风格的DSL【domain-specific language 领域特定语言】,被称为Query DSL
一个查询语句DSL的典型结构
QUERY_NAME是指定查询操作,查询操作非常多,在kibana中可以看到相应的提示,这里只介绍常用的,完整的列表以后再补ARGUMENT: VALUE是对查询操作的进一步配置
xxxxxxxxxx{QUERY_NAME: {ARGUMENT: VALUE,ARGUMENT: VALUE,}}针对一个字段的DSL典型结构
xxxxxxxxxx{QUERY_NAME: {FIELD_NAME: {ARGUMENT: VALUE,ARGUMENT: VALUE,}}}常用的查询DSL以及相关
QUERY_NAME举例query定义查询的方法,match_all表示查询所有内容sort表示查询结果列表的排序方式,可以多字段组合排序,表示在前序字段相等的条件下后续字段依次内部排序,前序字段不等以前序为准from和size组合完成分页功能,from表示第一个结果在排序列表中的位次,size表示当前页显示的记录条数_source指定返回结果只包含指定的字段,属性值为字段名数组,不写表示返回完整文档
xxxxxxxxxx{"query": {"match_all": {}},"from": 0,"size": 5,"sort": [{"account_number": {"order": "desc"}}]"_source": ["age","balance"]}query.match的用法一般的使用规定是,查询非
text字段都使用term进行查询,文本字段的全文检索使用match来进行查询,多词条字符串的精确全文检索用match_phrase,字段值的完全精确匹配用match查询中的keyword基本类型【非字符串】的精确匹配
表示精确匹配索引bank下
account_number字段等于20的文档记录,这个20用字符串或者单纯的数字都是可以的
xxxxxxxxxxGET bank/_search{"query": {"match": {"account_number": "20"}}}字符串单个单词的全文检索
match检索字符串时会进行全文检索,查询出
address字段包含对应字符串milld的所有记录,并给出每条记录的相关性评分
xxxxxxxxxxGET bank/_search{"query": {"match": {"address": "mill"}}}字符串多个单词的全文检索
这种以空格分隔的字符串,ES会将检索字符串进行分词、词条过滤处理后再分别到倒排索引表中进行匹配,最终查询出address字段中包含
mill或者road或者mill road的所有记录,并给出相关性得分
xxxxxxxxxxGET bank/_search{"query": {"match": {"address": "mill road"}}}字符串的字段值精确匹配
字段.keyword会让字段值完整精确匹配检索字符串,必须字段值完全等于检索字符串才会被查询到
xxxxxxxxxxGET bank/_search{"query": {"match": {"address.keyword": "789 Madison Street"}}}
query.match_phrase的用法字符串多个单词不分词进行全文检索
查出字段
address中包含mill road的所有记录并给出相关性评分,注意是否区分大小写要看分词器的具体类型,默认的是不区分大小写的
xxxxxxxxxxGET bank/_search{"query": {"match_phrase": {"address": "mill road"}}}
query.multi_match的用法查询多个字段同时包含指定字符串的查询
查出字段
state或者address有一个或者同时包含字符串mill的文档记录,注意这种方式的检索字符串也是会分词的,即"query": "mill road"会分词查询出对应字段包含mill或者road的文档记录
xxxxxxxxxxGET bank/_search{"query": {"multi_match": {"query": "mill","fields": ["state","address"]}}}
bool的用法bool用于复合查询,用法是合并任何其他查询语句即QUERY_NAME,复合语句可以相互嵌套,可以组合出非常复杂的逻辑must表示必须满足must列举的所有条件,示例如下查询同时满足
address字段含有字符串mill,gender字段含有字符串M的
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{ "match": { "address": "mill" } },{ "match": { "gender": "M" } }]}}}range表示筛选出字段满足指定范围的文档记录
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{"range": {"age": {"gte": 18,"lte": 20}}},{"match": {"address": "mill"}}]}}}term的用法term会精确匹配对应的检索词条,而且在对text类型的字段【即字段值为字符串类型】的时候,由于文档进行了分词,但是term中的检索词条不会进行分词,即便文档对应字段数据和term的检索字符串一模一样,也无法检索到属性值相同的那个文档数据,因此term常用来做非text字段的精确匹配,注意经过测试是精确匹配,而且只会精确匹配非text类型的字段
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{"term": {"age": {"value": "28"}}},{"match": {"address": "990 Mill Road"}}]}}}should的查询条件不会影响查询结果,只会影响查询结果的评分,满足should中查询条件会增加文档的评分,如果query中只有should且should中只有一种匹配规则,should的条件会作为默认匹配条件改变查询的结果查询索引
bank下同时满足address字段含有词条mill,gender字段含有词条M的文档记录,优先展示address字段含有lane词条的文档记录
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{ "match": { "address": "mill" } },{ "match": { "gender": "M" } }],"should": [{"match": { "address": "lane" }}]}}}must_not表示查询到的文档必须满足不是指定的查询条件查询索引
bank下同时满足address字段含有词条mill以及gender字段含有词条M,且email字段不含有词条baluba.com的文档记录,优先展示address字段含有lane词条的文档记录
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{ "match": { "address": "mill" } },{ "match": { "gender": "M" } }],"should": [{"match": { "address": "lane" }}],"must_not": [{"match": { "email": "baluba.com" }}]}}}filter的用法bool中的must和should中的查询条件满足是会增加文档相关性评分的,must_not中的条件不会影响相关性评分;filter中的条件也不会影响相关性评分
filter中的条件可能和must中的条件一致,比如range要求筛选出某个字段在一定范围内的文档记录,请求的写法分别为
【must筛选范围】
must中没有match只有这个range也会有相关性得分
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{"range": {"age": {"gte": 18,"lte": 20}}},{"match": {"address": "mill"}}]}}}【filter筛选范围】
filter会将记录中不满足预设条件的文档记录直接过滤清除掉
满足filter中范围条件的文档记录的_score字段每条记录都为0,这是因为只进行了filter过滤,filter本身不计算得分,如果filter还组合了其他如should等条件,得到的记录还是会有相关性评分,比如以下这个含must的还是有评分数据的
xxxxxxxxxxGET bank/_search{"query": {"bool": {"must": [{"match": { "address": "mill"}}],"filter": {"range": {"balance": {"gte": 10000,"lte": 20000}}}}}}
Aggregation聚合分析相关
聚合功能是ES提供的数据分组和提取数据的功能,聚合类型比较多,有三类好几十种,这里主要讲terms和avg,其他的一些常用聚合函数后边用到再总结
聚合查询语法
aggregation_name是聚合操作的具体名称,aggregation_type是指定聚合操纵的类型,aggregation_body是指定聚合体【聚合体一般都指定field属性表示要聚合的字段以及size指定要展示的数据条数】,meta是指定聚合操作的元数据一个总的聚合查询语句中可以指定多个平行的聚合操作如
aggregation_name_2,也可以使用第一次聚合aggregation_name的结果再次发起聚合操作sub_aggregation【注意啊,这个操作只是把上次聚合的结果作为新聚合操作的分组,实际上你可以在年龄分组操作后再对同一个分组的薪资进行聚合操作】,sub_aggregation称为子聚合aggregations可以缩写为aggs
xxxxxxxxxx"aggregations" : {"<aggregation_name>" : {"<aggregation_type>" : {<aggregation_body>}[,"meta" : { [<meta_data_body>] } ]?[,"aggregations" : { [<sub_aggregation>]+ } ]?}[,"<aggregation_name_2>" : { } ]*}一个查询操作多个平行聚合操作
搜索bank索引中的address字 段包含
mill的所有人的年龄分布以及平均年龄,但是不显示对应的记录详情aggs表示对query中的查询结果执行聚合操作,group_by_state是当前聚合的名字,term是一种聚合的类型AGG_TYPE,其他的聚合类型包括avg、termssize为0表示不显示query对应的即hits中的搜索数据
xxxxxxxxxxGET bank/_search{"query": {"match": {"address": "mill"}},"aggs": {"group_by_state": {"terms": {"field": "age","size": 10}},"avg_age": {"avg": {"field": "age"}}},"size": 0}响应结果
其中
hits中显示query查询的结果,因为size为0所以不显示查询结果,注意这个size也可以在aggs中的聚合类型内部使用,作用是只显示聚合结果中的前size条数据aggregations中显示聚合操作的结果,每个聚合操作的json结果都以聚合操作的名字作为json对象的名字,doc_count_error_upper_bound是聚合中发生的错误信息,sum_other_doc_count是本次聚合操作统计到的其他文档的数量,buckets意思是桶,桶中的每个json对象都是一个统计结果,key表示一个结果的统计值,doc_count表示当前统计值下的文档记录数量,比如年龄为38的文档有2个,avg_age是第二个聚合操作的结果,value显示当前所有文档的平均年龄
xxxxxxxxxx{"took" : 17,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"avg_age" : {"value" : 34.0},"group_by_state" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 38,"doc_count" : 2},{"key" : 28,"doc_count" : 1},{"key" : 32,"doc_count" : 1}]}}}
一个聚合操作含有子聚合操作的查询
按照年龄进行分组聚合,并对每个年龄分组求这些年龄段的人的平均薪资
xxxxxxxxxxGET bank/account/_search{"query": {"match_all": {}},"aggs": {"age_avg": {"terms": {"field": "age","size": 1000},"aggs": {"banlances_avg": {"avg": {"field": "balance"}}}}},"size": 0}响应结果
xxxxxxxxxx{"took" : 9,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"age_avg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 31,"doc_count" : 61,"banlances_avg" : {"value" : 28312.918032786885}},{"key" : 39,"doc_count" : 60,"banlances_avg" : {"value" : 25269.583333333332}},{"key" : 29,"doc_count" : 35,"banlances_avg" : {"value" : 29483.14285714286}}]}}}
对文本字段的聚合操作需要使用
字段.keyword,同时子聚合中使用多个并行聚合操作对所有年龄分组, 并且这些年龄段中字段gender为M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资
xxxxxxxxxxGET bank/account/_search{"query": {"match_all": {}},"aggs": {"age_agg": {"terms": {"field": "age","size": 100},"aggs": {"gender_agg": {"terms": {"field": "gender.keyword","size": 100},"aggs": {"balance_avg": {"avg": {"field": "balance"}}}},"balance_avg":{"avg": {"field": "balance"}}}}},"size": 0}响应结果
xxxxxxxxxx{"took" : 5,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"age_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 879,"buckets" : [{"key" : 31,"doc_count" : 61,"balance_avg" : {"value" : 28312.918032786885},"gender_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "M","doc_count" : 35,"balance_avg" : {"value" : 29565.628571428573}},{"key" : "F","doc_count" : 26,"balance_avg" : {"value" : 26626.576923076922}}]}},{"key" : 39,"doc_count" : 60,"balance_avg" : {"value" : 25269.583333333332},"gender_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "F","doc_count" : 38,"balance_avg" : {"value" : 26348.684210526317}},{"key" : "M","doc_count" : 22,"balance_avg" : {"value" : 23405.68181818182}}]}}]}}}
Mapping映射
字段类型
类型的所有分类见官方文档的Field datatypes,Mapping Type【即一个索引下有一个或者多个文档类型的类型】在ES 6.0版本已经被宣称过时并移除,原因是在Lucene中ES不同的文档类型但是名称相同的字段属性在Lucene中的处理方式是一样的,这种基于Lucene的对字段的处理方式要求在不同的类中定义相同的字段属性,否则不同定义的不同类型中同名字段属性在处理的时候就会发生冲突,导致Lucene的处理效率下降,因此废除类型怪你按就是为了提高ES的处理效率,这里的Mapping指的是数据类型
ES 7.x中URL中的type参数仍然是可选选项,但是已经修改为索引一个文档不再要求提供文档类型
ES 8.x中已经不在支持URL中的type参数,而是将索引从多类型迁移到单类型,每种类型文档一个独立的索引
核心类型
字符串
text
keyword
数字类型
long
integer
short
byte
double
float
half_float
scaled_float
日期类型
date
date_nanos
兼容纳秒的日期类型
布尔类型
boolean
二进制类型
binary
复合类型
数组类型
Array
对象类型
Object
Object类型用于单JSON对象
嵌套类型
nested
nested用于JSON对象数组
地理类型
地理坐标Geo
地理坐标Geo-points
Geo-points用于描述经纬度坐标
地理图形Geo-Shape
Geo-Shape用于描述多边形等复杂形状
特定类型
IP类型
ip用于描述ipv4和ipv6
补全类型Completion
completion提供自动完成提示
令牌计数类型Token count
token_count用于统计字符串的词条数量
附件类型attachment
参考mapper-attachements插件,支持将附件如Microsoft Office格式、Open Document格式、ePub、HTML等等索引为attachment数据类型
多字段muti-fields
概念
为了满足业务场景使用不同的方法同时索引同一个字段
如String类型字段可以同时映射为一个text字段用于全文检索,或者一个keyword字段用于排序和聚合,此外text字段还可以被各种类型的分析器standard analyzer、english analyzer、french analyzer来进行分词并建立索引
映射Mapping
概念
Mapping用于定义一个文档所包含的属性field是如何存储和被索引的,使用mapping可以定义:
哪些字符串属性应该被看做全文本属性
full text field哪些属性为数字类型、日期类型或者地理位置类型
文档中所有属性是否都能被索引
mapping还可以定义日期的格式
自定义映射规则来执行动态添加属性
索引一个文档,文档数据的类型会被ES自动进行类型猜测,这些映射可以在索引数据后修改,也可以在索引数据前进行指定
数字都会被猜测为long
字符串都会被猜测为文档text,且每个文本默认都会有对应的keyword子类型
API
【GET】
http://192.168.567.10:9200/bank/_mapping请求体:无
功能:查看索引下的映射信息
响应内容:
properties会显示所有字段的类型text类型会自动进行全文检索,对对应的文档信息进行分词分析,同时一个字段还可以有子类型fields,表示address字段还可以是keyword这种类型,表示该字段值可以被完全精确匹配
xxxxxxxxxx{"bank" : {"mappings" : {"properties" : {"account_number" : {"type" : "long"},"address" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"age" : {"type" : "long"},"balance" : {"type" : "long"},"state" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}}
【PUT】
http://192.168.56.10:9200/my-index请求体:
可以直接指定字段数据类型为keyword,注意这种指定方式指定的text没有子数据类型keyword,指定为keyword的类型和text类型也没有关系
xxxxxxxxxx{"mappings": {"properties": {"age": { "type": "integer" },"email": { "type": "keyword" },"name": { "type": "text" }}}}功能:创建索引
my-index的同时为索引指定映射规则响应内容:
xxxxxxxxxx{"acknowledged" : true,"shards_acknowledged" : true,"index" : "my_index"}【索引映射】
xxxxxxxxxx{"my_index" : {"mappings" : {"properties" : {"age" : {"type" : "integer"},"email" : {"type" : "keyword"},"name" : {"type" : "text"}}}}}补充说明:
不能再次使用该请求并在请求体中修改映射规则如请求体如下,实际上不更改映射规则也会报错,报错信息是目标索引已经存在
xxxxxxxxxx{"mappings": {"properties": {"age": { "type": "integer" },"email": { "type": "keyword" },"name": { "type": "text" },"employee_id": {"type": "long"}}}}响应内容
xxxxxxxxxx{"error": {"root_cause": [{"type": "resource_already_exists_exception","reason": "index [my_index/fb9JRcDTShyvbPWoq7vriQ] already exists","index_uuid": "fb9JRcDTShyvbPWoq7vriQ","index": "my_index"}],"type": "resource_already_exists_exception","reason": "index [my_index/fb9JRcDTShyvbPWoq7vriQ] already exists","index_uuid": "fb9JRcDTShyvbPWoq7vriQ","index": "my_index"},"status": 400}每个映射的数据类型在定义的时候都默认添加了
"index": true,即xxxxxxxxxx{"mappings": {"properties": {"employee_id": {"type": "long","index": true}}}}意思是当前字段属性会被索引并能被检索,如果将index设置为false,则该字段不会被索引,也无法通过该字段索引文档,该属性只是作为文档的冗余存储
【PUT】
http://192.168.56.10:9200/my_index/_mapping请求体:
xxxxxxxxxx{"properties": {"employee_id": {"type": "keyword","index": false}}}作用:为索引新增映射
响应内容:
xxxxxxxxxx{"acknowledged" : true}【此时对应索引下的映射信息】
xxxxxxxxxx{"my_index" : {"mappings" : {"properties" : {"age" : {"type" : "integer"},"email" : {"type" : "keyword"},"employee_id" : {"type" : "keyword","index" : false},"name" : {"type" : "text"}}}}}补充说明:
注意这种方式不能用于修改当前已经存在的映射关系,如不能把
email的数据类型改为text官方规定了已经存在的映射关系是不能修改的,变更一个已经存在的映射可能会导致已经存在的数据失效【比如检索规则】,如果是在需要变更某个字段的映射关系,官方建议创建一个新的索引并设置新的映射规则,并且索引老索引下的所有旧数据到新索引下,也即把旧数据迁移到被设置正确映射关系的新索引下
【POST】
http://192.168.56.10:9200/_reindex请求体:
【旧索引不含类型的情况】
该WEB API的作用是在两个不同的索引间迁移所有的数据
dest表示设置目标索引的位置、source表示旧索引的位置,index属性都填写对应的索引名
注意啊,经过测试,原来的索引有mapping映射而且新索引也有不同的mapping映射也一样可以通过该方式进行数据迁移,不需要指定类型
xxxxxxxxxx{"source": {"index": "twitter"},"dest": {"index": "new_twitter"}}【旧索引包含类型的情况】
即需要指定旧索引的索引和类型,新索引只需要指定索引不需要指定类型
❓:如果一个索引下有多个类型怎么办,可以把
type写成数组吗❓:如何查询一个索引下的全部文档类型
xxxxxxxxxx{"source": {"index": "bank","type": "account"},"dest": {"index": "new_bank"}}
分词器Tokenizer
分词器接收一个字符流,将其分割为独立的词条Token【也叫词元】,然后输出tokens流
ES提供很多内置的分词器,实际上是内置很多的字符过滤器,分词器和词条过滤器,三者公共构成分析器,通过这些过滤器和分析器,我们可以自定义各种类型的词条分析器
whitespace tokenizer遇到空白字符会分割文本,该分词器还负责记录各词条的顺序或者位置用于做短语查询或者临近词条的查询,还会记录词条对应的原始单词的字符偏移量【即起始字符和结束字符的下标】用于高亮显示搜索的内容等功能
分词器在官方文档的Analysis章节
分词相关API
【POST】
http://192.168.56.10:9200/_analyze请求体:
xxxxxxxxxx{"analyzer": "standard","text": "我是中国人!"}功能:使用标准分析器对指定文本进行分析并响应分析结果,
analyzer是指定分析器,常用的分析器有standard、ik响应内容:
xxxxxxxxxx{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "<IDEOGRAPHIC>","position" : 0},{"token" : "是","start_offset" : 1,"end_offset" : 2,"type" : "<IDEOGRAPHIC>","position" : 1},{"token" : "中","start_offset" : 2,"end_offset" : 3,"type" : "<IDEOGRAPHIC>","position" : 2},{"token" : "国","start_offset" : 3,"end_offset" : 4,"type" : "<IDEOGRAPHIC>","position" : 3},{"token" : "人","start_offset" : 4,"end_offset" : 5,"type" : "<IDEOGRAPHIC>","position" : 4}]}补充说明:
标准分析器对英文文档会以空格作为标准对文档进行分词,对待中文的处理方式是直接分词到字,这种方式很不好,而且ES中内置的大多数分析器都是针对英文的,一般对中文的分析都使用ik分词器
ik分词器
ik分词器有两种常用的分词器
ik_smart、ik_max_word,不能直接指定分词器为ik,会报错
测试
ik_smart分词器【POST】
http://192.168.56.10:9200/_analyze请求体:
xxxxxxxxxx{"analyzer": "ik_smart","text": "我是中国人!"}功能:使用ik分词器的
ik_smart分词器分析文档我是中国人!,该分词器会尽可能按文档意思按最粗粒度进行分词,但是不会分词到字响应结果:
xxxxxxxxxx{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "是","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1},{"token" : "中国人","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 2}]}补充说明:
标点符号是不进行索引的,默认无法识别自定义词
测试
ik_max_word分词器【POST】
http://192.168.56.10:9200/_analyze请求体:
xxxxxxxxxx{"analyzer": "ik_max_word","text": "我是中国人!"}功能:使用
ik_max_word分词器分析我是中国人!,该分词器会尽可能找到每一个短语,即便每个字被多次使用,但是不会分词到单个字响应内容:
xxxxxxxxxx{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "是","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1},{"token" : "中国人","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 2},{"token" : "中国","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 3},{"token" : "国人","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 4}]}补充说明:
默认无法识别自定义词,如
尚硅谷
自定义ik扩展词库
对一些网络热词或者公司名字等词汇,ik分词器不能很好地识别,这时候我们可以配置自己的本地词库或者远程词库并在ik分词器的配置文件中进行配置
配置远程词库可以自己写一个项目,让ik分词器处理过程中向我们自己的项目发送请求;也可以配置nginx,将最新的词库放在nginx中,让ik分词器给nginx发送请求
这里使用Nginx配置远程词库的方式,原来的虚拟机1G内存现在已经不够用了,使用命令
free -m能看到当前的内存只有100来MB了,将虚拟机的内存修改为3G,由于ES的虚拟机内存此前只设置了512M也太小了,可能会导致ES运行中出现各种各样的问题,把容器实例删了重新创建容器实例,由于容器数据卷进行了挂载,重新创建容器实例指定相同的容器数据卷不会导致数据发生丢失
在nginx上搭建远程词库
1️⃣:参考整合Elasticsearch--环境安装安装nginx容器实例
2️⃣:在容器数据卷nginx的静态资源目录
/malldata/nginx/html下创建es目录专门存放ik分词器使用到的远程词库,在es目录下创建文件ik_remote_lexicon.txt,在文件中输入以下词条本质上是将词典从本地弄成网络资源供ik分词器自己去获取,区别只是ik分词器从ES本地获取或者从网络获取
xxxxxxxxxx尚硅谷乔碧萝3️⃣:使用命令
vi /malldata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml修改ik分词器的配置文件内容如下打开配置远程字典的配置注释,填入词典的URL地址
http://192.168.56.10/es/ik_remote_lexicon.txt
xxxxxxxxxx<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict"></entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><entry key="remote_ext_dict">http://192.168.56.10/es/ik_remote_lexicon.txt</entry><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>4️⃣:使用命令
docker restart elasticsearch重启容器实例5️⃣:使用ES的ik分词API尝试索引包含对应词条的文档,观察相应词条是否索引成功
【POST】
/analyzexxxxxxxxxx{"analyzer": "ik_max_word","text": "尚硅谷的乔碧萝"}响应结果
xxxxxxxxxx{"tokens" : [{"token" : "尚硅谷","start_offset" : 0,"end_offset" : 3,"type" : "CN_WORD","position" : 0},{"token" : "硅谷","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 1},{"token" : "的","start_offset" : 3,"end_offset" : 4,"type" : "CN_CHAR","position" : 2},{"token" : "乔碧萝","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 3}]}
Elasticsearch-Rest-Client
业务中检索请求的处理逻辑是前端发起检索请求给后端Java服务器,Java服务器向ES服务器发起检索请求获取数据并响应给前端,Java客户端操作ES的方式有两种
第一种方式是使用
spring-data-elasticsearch:transport-api.jar通过ES的TCP端口9300,也即节点间的通信端口;这种方式SpringBoot版本不同,对应的transport-api.jar也不同,更换ES的版本就要更换对应的transport-api.jar和SpringBoot的版本,而且ES版本对应的transport-api.jar根本就没出或者SpringBoot压根还没整合,这样不好;其次7.x版本已经不建议使用transport-api.jar,8以后就直接准备废弃了通过9300端口操作ES的jar包第二种方式是通过HTTP协议走9200端口发送请求操作ES,市面上通过这种方式操作ES的产品有
JestClient:非官方,更新慢,从maven仓库可以查询到最近版本的更新时间,比较慢,落后ES好几个小版本
RestTemplate:这个产品只是模拟发送HTTP请求,ES很多操作需要自己进行封装,封装起来很麻烦
HttpClient:该产品也只是模拟发送HTTP请求,ES的相关请求和响应数据处理需要自己封装,很麻烦;像这些只能用来发送HTTP请求的如OKHTTP等等都可以操作ES,但是DSL语句和响应结果需要自己封装工具进行处理
Elasticsearch-Rest-Client:官方RestClient,封装了ES操作,API层次比较分明,官方的ES发布到哪个版本,这个工具也会同时更新相应的版本,本项目就使用该客户端
据说有个开源的ebatis,用起来也非常爽
Elasticsearch-Rest-Client的官方文档在ES的Docs中的Elasticsearch Clients章节,里面列举了各种语言对ES的操作API,其中还有JavaScript客户端,但是ES一般属于后台服务器集群中一部分,一般不直接对外暴露,暴露可能会被公网恶意利用;使用js操作也不需要使用ES官方的工具,直接用js发送请求即可;Java API是基于9300端口操作ES的【而且文档标记7.0版本已经过时,在8.0版本将移除,在文档中推荐使用Java High Level REST Client,Java High Level REST Client是Java REST Client中两个工具的一种,还有一种是Java Low Level REST Client,两者的关系相当于mybatis
和JDBC 的关系;现在8.13版本都过时了,现在只有一个 Java Client了】,Java REST Client是基于9200端口操作ES的❓:为什么不用js发送查询请求,由nginx进行转发呢,还是因为安全的原因吗?反正就是用后端服务器调用来查询,以后再去看实际的情况
创建一个单独的模块
mall-search来使用Elasticsearch-Rest-Client中的Java High Level REST Client来操作ES服务器集群
搭建操作ES的模块
1️⃣:创建模块
mall-search,勾选整合Web中的Spring Web说明:NoSQL中有个Spring Data Elasticsearch因为最新只整合到6.3版本的ES【当时ES的最新版本是7.4】,所以就不考虑SpringData Elasticsearch,如果ES使用的版本不是那么新,选择SpringData Elasticsearch其实也是很好的选择,相比于官方的Elasticsearch-Rest-Client做了更简化的封装
2️⃣:导入
Java High Level REST Client的maven依赖,将版本号改为对应ES服务器的版本号,将ES服务器的版本号在properties标签中进行重新指定注意通过右侧的maven依赖树能够看到elasticsearch-rest-high-level-client虽然版本是7.4.2,但是子依赖中的部分版本还是6.8.5,这是因为SpringBoot对ES的版本进行了默认仲裁,SpringBoot2.2.2.RELEASE当引入SpringData Elasticsearch会自动仲裁Elasticsearch的版本为6.8.5【点开父依赖中的
spring-boot-starter-parent的父依赖的spring-boot-dependencies能够看见相关的版本信息】
xxxxxxxxxx<!--导入es的rest-high-level-client--><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.4.2</version></dependency>更改SpringBoot对Elasticsearch的版本自动仲裁,刷新maven直到依赖树中的相关依赖版本全部变成7.4.2
xxxxxxxxxx<properties><elasticsearch.version>7.4.2</elasticsearch.version></properties>
3️⃣:对
rest-high-level-client进行配置🔎:如果使用SpringData Elasticsearch对ES操作,配置就非常简单,这个在ES的整合SpringData Elasticsearch中已经实现了,这里要配置我们自己选择的
rest-high-level-client会稍微复杂一些编写配置类
MallElasticsearchConfig并注入IoC容器,这个配置类参考ES的官方文档Java High Level REST Client中的Getting started中的Initialization需要创建一个
RestHighLevelClient实例client,通过该实例来创建ES的操作对象
【单节点集群的创建客户端实例】
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 对Java High Level REST Client进行配置,配置ES操作对象* @创建日期 2024/05/24* @since 1.0.0*/public class MallElasticSearchConfig {/*** @return {@link RestHighLevelClient }* @描述 通过单节点集群的ip地址和端口以及通信协议名称来创建RestHighLevelClient对象* @author Earl* @version 1.0.0* @创建日期 2024/05/24* @since 1.0.0*/public RestHighLevelClient esRESTClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.56.10", 9200, "http")));return client;}}【多节点集群下的创建客户端实例】
多节点集群就在
RestClient.builder(HttpHost...)方法中的可变长度参数列表中输入各个节点的IP信息
xxxxxxxxxxpublic RestHighLevelClient esRESTClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http"),new HttpHost("localhost", 9201, "http")));return client;}
4️⃣:导入模块
mall-common引入注册中心【这里面引入的其他依赖挺多的,包含mp、Lombok、HttpCore、数据校验、Servlet API等】,配置配置中心、注册中心,服务名称在主启动类上使用注解@EnableDiscoveryClient开启服务的注册发现功能,在主启动类使用@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)排除数据源【配置中心
bootstrap.properties配置】注意
bootstrap.properties文件必须在引入nacos的配置中心依赖后才会展示出小叶子图标
xxxxxxxxxxspring.application.name=mall-stockspring.cloud.nacos.config.server-addr=127.0.0.1:8848spring.cloud.nacos.config.namespace=9c29064b-64f8-4a43-9375-eceb6e3c79575️⃣:编写测试类检查ES操作对象是否创建成功
只要能打印出client对象,说明成功连接并创建ES操作对象,后续只需要参考官方文档使用对应的API即可,对应的文档也在
Java High Level REST Client中的所有APIs部分
xxxxxxxxxx(SpringRunner.class)public class MallSearchApplicationTests {private RestHighLevelClient esRESTClient;public void contextLoads() {System.out.println(esRESTClient);//org.elasticsearch.client.RestHighLevelClient@3c9c6245}}
Java High Level REST Client API
RequestOptions
RequestOptions是请求设置项,ES添加了安全访问规则的情况下,所有的请求都必须携带一些安全相关的头信息,通过RequestOptions来对所有请求做一些统一设置,设置的文档在Java Low Level REST Client的文档
官方建议将RequestOptions做成单实例,所有请求都来共享这一个单实例RequestOptions,使用RequestOptions的各类型builder来为请求头添加各种头信息,比如头Authorization=Bearer+授权令牌,还可以使用builder来自定义响应的消费者,比如和异步相关的HttpAsyncResponseconsumerFactory
将RequestOptions添加至
mall-search模块的统一配置类中配置实例
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 对Java High Level REST Client进行配置,配置ES操作对象、RequestOptions对象* @创建日期 2024/05/24* @since 1.0.0*/public class MallElasticSearchConfig {public static final RequestOptions COMMON_OPTIONS;//这里可以结合单实例的五种方式有时间看看哪种好static {RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();//以下是RequestOptions的各种配置,按需要到时候再添加//builder.addHeader("Authorization","Bearer"+TOKEN);//builder.setHttpAsyncResponseConsumerFactory(// new HttpAsyncResponseConsumerFactory// .HeapBufferedResponseConsumerFactory(30*1024*1024*1024)//);COMMON_OPTIONS=builder.build();}/*** @return {@link RestHighLevelClient }* @描述 通过单节点集群的ip地址和端口以及通信协议来创建RestHighLevelClient对象* @author Earl* @version 1.0.0* @创建日期 2024/05/24* @since 1.0.0*/public RestHighLevelClient esRESTClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.56.10", 9200, "http")));return client;}}
Document APIs
索引文档到ES
使用IndexRequest对象来索引一个文档,创建IndexRequest对象时指定索引名称,也可以创建IndexRequest以后指定,IndexRequest对象中大部分属性都有对应的同名方法来传参对应的属性值,如index和id等;ES服务器中没有对应索引会自动创建同名索引;而且该api是保存更新操作二合一,多次操作会更新版本号
可以使用各种工具来将文档数据对象转换为json格式的字符串
indexRequest的source方法是传参文档数据,支持如下多种参数类型,最常用的是直接传参一个json字符串
文档数据参数类型1:JSON字符串
注意传递JSON格式的数据一定要指定内容类型为
XContentType.JSON,否则会报错提示传参的Object对象只有一个
xxxxxxxxxxIndexRequest request = new IndexRequest("posts");request.id("1");String jsonString = "{" +"\"user\":\"kimchy\"," +"\"postDate\":\"2013-01-30\"," +"\"message\":\"trying out Elasticsearch\"" +"}";request.source(jsonString, XContentType.JSON);文档数据参数类型2:Map集合
xxxxxxxxxxMap<String, Object> jsonMap = new HashMap<>();jsonMap.put("user", "kimchy");jsonMap.put("postDate", new Date());jsonMap.put("message", "trying out Elasticsearch");IndexRequest indexRequest = new IndexRequest("posts").id("1").source(jsonMap);文档数据参数类型3:K-V键值对构造的
XContentBuilder,直接在大括号内用XContentBuilder的相关方法传递键值对数据xxxxxxxxxxXContentBuilder builder = XContentFactory.jsonBuilder();builder.startObject();{builder.field("user", "kimchy");builder.timeField("postDate", new Date());builder.field("message", "trying out Elasticsearch");}builder.endObject();IndexRequest indexRequest = new IndexRequest("posts").id("1").source(builder);文档数据参数类型4:可变长度参数列表直接传入键值对
xxxxxxxxxxIndexRequest indexRequest = new IndexRequest("posts").id("1").source("user", "kimchy","postDate", new Date(),"message", "trying out Elasticsearch");
传参JSON字符串代码实例
xxxxxxxxxx(SpringRunner.class)//指定使用Spring的驱动来跑单元测试,这是老版本SpringBoot的写法,新版本已经不这么写了public class MallSearchApplicationTests {private RestHighLevelClient esRESTClient;/*** @描述 IndexAPI索引一个文档* @author Earl* @version 1.0.0* @创建日期 2024/05/27* @since 1.0.0*/public void indexDoc() throws IOException {//创建IndexRequest对象,构建的时候指定文档对应的索引名称IndexRequest indexRequest = new IndexRequest("users");//指定文档的id,文档id的类型要求传入String类型indexRequest.id("1");//构建一个文档数据对象User user = new User("张三","男",18);//使用fastjson来将文档数据对象处理成json字符串,注意nacos-discovery中的父依赖nacos-api中引入了fastjson,可以直接用String userJSONStr = JSON.toJSONString(user);//indexRequest.source(userJSONStr);传入要索引的文档数据,支持的方式有四种,最常用的就是传入json字符串的方式indexRequest.source(userJSONStr);//执行索引文档的操作,要传参RequestOptionsIndexResponse response = esRESTClient.index(indexRequest, MallElasticSearchConfig.COMMON_OPTIONS);System.out.println(response);//}class User{private String userName;private String gender;private Integer age;}}IndexRequest中还可以设置文档保存超时时间、刷新策略、版本号等等
文档数据的保存可以分为同步和异步两种方式,同步是等待保存操作执行结束再继续执行后续代码,异步是不等待数据继续执行后续代码用监听器监听响应后执行回调,暂时先不考虑异步的问题,上述代码使用的是同步的索引文档操作
Search APIs
文档中包含了所有对文档的检索操作和聚合查询操作,做检索都是通过构建SearchRequest对象来封装检索条件实现的
检索和聚合文档记录
使用
searchRequest.source(searchSourceBuilder);来封装检索条件用
esRESTClient.search(searchRequest,MallElasticSearchConfig.COMMON_OPTIONS)来执行检索操作用
searchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));来封装词条检索条件用
searchSourceBuilder.from();和searchSourceBuilder.size();来封装分页操作用
searchSourceBuilder.aggregation(AggregationBuilders.terms("ageByGroup").field("age").size(10));来封装值分布聚合操作条件用
searchSourceBuilder.aggregation(AggregationBuilders.avg("balanceAvg").field("balance"));来封装均值聚合操作条件带条件检索和Terms值分布和AVG均值聚合操作的代码实例
以下代码前半部分是发起带聚合的检索操作
后半部分是获取响应的记录以及聚合操作的结果
xxxxxxxxxx(SpringRunner.class)public class MallSearchApplicationTests {private RestHighLevelClient esRESTClient;/*** @描述 检索和聚合操作满足条件的文档* @author Earl* @version 1.0.0* @创建日期 2024/05/27* @since 1.0.0*/public void searchDoc() throws IOException {//创建检索请求SearchRequest searchRequest = new SearchRequest();//指定检索文档的索引范围,是可变长度参数列表,表示可以从1个或者多个索引下检索文档searchRequest.indices("bank");//通过SearchSourceBuilder来构建检索条件,用searchRequest来封装检索条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//用SearchSourceBuilder来构建检索条件,在文档的Using the SearchSourceBuilder部分,这里面的根属性和DSL的json对象的对象名是一样的//而且都使用链式编程的方式//query方法需要传参QueryBuilder,QueryBuilders是QueryBuilder对应的工具类,可以快速方便地生成QueryBuilder//QueryBuilders中有matchQuery方法对应DSL中的match,有matchAllQuery方法对应DSL中的matchAll,传参键值对String-ObjectsearchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));//searchSourceBuilder.from();//searchSourceBuilder.size();//构造聚合条件,聚合函数aggregation中需要传参封装聚合查询参数的AggregationBuilder,相应的也有对应的工具类AggregationBuilders快速构建AggregationBuilder//构造第一个聚合//terms聚合函数用于对字段统计分组[按字段的值分布进行聚合],传参本次聚合的名字,用于存放返回的聚合信息,链式调用来设置要统计的字段和返回的记录条数等searchSourceBuilder.aggregation(AggregationBuilders.terms("ageByGroup").field("age").size(10));//构造第二个聚合//对薪资进行平均值聚合,每个聚合都要使用searchSourceBuilder.aggregation对每个searchBuilder都进行聚合searchSourceBuilder.aggregation(AggregationBuilders.avg("balanceAvg").field("balance"));System.out.println(searchSourceBuilder);//除了我们设置的检索条件外,还添加了很多默认设置,如boost,默认是1.0,是设置当前检索条件的权重/*** {* "query": {* "match": {* "address": {* "query": "mill",* "operator": "OR",* "prefix_length": 0,* "max_expansions": 50,* "fuzzy_transpositions": true,* "lenient": false,* "zero_terms_query": "NONE",* "auto_generate_synonyms_phrase_query": true,* "boost": 1.0* }* }* },* "aggregations": {* "ageByGroup": {* "terms": {* "field": "age",* "size": 10,* "min_doc_count": 1,* "shard_min_doc_count": 0,* "show_term_doc_count_error": false,* "order": [* {* "_count": "desc"* },* {* "_key": "asc"* }* ]* }* },* "balanceAvg": {* "avg": {* "field": "balance"* }* }* }* }* */searchRequest.source(searchSourceBuilder);//执行检索操作,传参searchRequest和RequestOptionsSearchResponse searchResponse = esRESTClient.search(searchRequest,MallElasticSearchConfig.COMMON_OPTIONS);//searchResponse是检索结果,封装了检索信息,官方文档也介绍了各个属性的具体获取apiSystem.out.println(searchResponse);//响应结果中最重要的是命中记录和聚合结果的获取/**响应结果* {* "took": 3,* "timed_out": false,* "_shards": {* "total": 1,* "successful": 1,* "skipped": 0,* "failed": 0* },* "hits": {* "total": {* "value": 4,* "relation": "eq"* },* "max_score": 5.4032025,* "hits": [{* "_index": "bank",* "_type": "account",* "_id": "970",* "_score": 5.4032025,* "_source": {* "account_number": 970,* "balance": 19648,* "firstname": "Forbes",* "lastname": "Wallace",* "age": 28,* "gender": "M",* "address": "990 Mill Road",* "employer": "Pheast",* "email": "forbeswallace@pheast.com",* "city": "Lopezo",* "state": "AK"* }* }, {* "_index": "bank",* "_type": "account",* "_id": "136",* "_score": 5.4032025,* "_source": {* "account_number": 136,* "balance": 45801,* "firstname": "Winnie",* "lastname": "Holland",* "age": 38,* "gender": "M",* "address": "198 Mill Lane",* "employer": "Neteria",* "email": "winnieholland@neteria.com",* "city": "Urie",* "state": "IL"* }* }, {* "_index": "bank",* "_type": "account",* "_id": "345",* "_score": 5.4032025,* "_source": {* "account_number": 345,* "balance": 9812,* "firstname": "Parker",* "lastname": "Hines",* "age": 38,* "gender": "M",* "address": "715 Mill Avenue",* "employer": "Baluba",* "email": "parkerhines@baluba.com",* "city": "Blackgum",* "state": "KY"* }* }, {* "_index": "bank",* "_type": "account",* "_id": "472",* "_score": 5.4032025,* "_source": {* "account_number": 472,* "balance": 25571,* "firstname": "Lee",* "lastname": "Long",* "age": 32,* "gender": "F",* "address": "288 Mill Street",* "employer": "Comverges",* "email": "leelong@comverges.com",* "city": "Movico",* "state": "MT"* }* }]* },* "aggregations": {* "avg#balanceAvg": {* "value": 25208.0* },* "lterms#ageByGroup": {* "doc_count_error_upper_bound": 0,* "sum_other_doc_count": 0,* "buckets": [{* "key": 38,* "doc_count": 2* }, {* "key": 28,* "doc_count": 1* }, {* "key": 32,* "doc_count": 1* }]* }* }* }* *///获取响应状态码RestStatus status = searchResponse.status();//获取检索操作花费的时间TimeValue took = searchResponse.getTook();//检索操作是否提前终止Boolean terminatedEarly = searchResponse.isTerminatedEarly();//检索操作是否超时boolean timedOut = searchResponse.isTimedOut();//检索涉及的分片总数int totalShards = searchResponse.getTotalShards();//成功的分片数int successfulShards = searchResponse.getSuccessfulShards();//失败的分片数int failedShards = searchResponse.getFailedShards();//操作失败的分片检索for (ShardSearchFailure failure : searchResponse.getShardFailures()) {//对失败检索的自定义操作}//获取检索命中的记录,这里面包含命中记录总数和记录的数据SearchHits hits = searchResponse.getHits();//拿到命中记录的总记录数,其中的value才是确切的总记录数TotalHits totalHits = hits.getTotalHits();long value = totalHits.value;//记录的相关性得分TotalHits.Relation relation = totalHits.relation;//命中记录的最大得分float maxScore = hits.getMaxScore();//获取记录数据数组,这是真正命中的所有记录,每个记录都有对应的索引、类型、文档id和对应的文档评分,以及SearchHit[] searchHits = hits.getHits();for (SearchHit searchHit : searchHits) {//自定义对命中记录的操作//获取命中记录的索引String index = searchHit.getIndex();//获取命中记录的idString id = searchHit.getId();//获取命中记录的分数float score = searchHit.getScore();//将返回的命中记录转换为对应的json字符串,命中记录统一在名为_source的数组下/**** :{"account_number":970,"balance":19648,"firstname":"Forbes","lastname":"Wallace","age":28,"gender":"M","address":"990 Mill Road","employer":"Pheast","email":"forbeswallace@pheast.com","city":"Lopezo","state":"AK"}* :{"account_number":136,"balance":45801,"firstname":"Winnie","lastname":"Holland","age":38,"gender":"M","address":"198 Mill Lane","employer":"Neteria","email":"winnieholland@neteria.com","city":"Urie","state":"IL"}* :{"account_number":345,"balance":9812,"firstname":"Parker","lastname":"Hines","age":38,"gender":"M","address":"715 Mill Avenue","employer":"Baluba","email":"parkerhines@baluba.com","city":"Blackgum","state":"KY"}* :{"account_number":472,"balance":25571,"firstname":"Lee","lastname":"Long","age":32,"gender":"F","address":"288 Mill Street","employer":"Comverges","email":"leelong@comverges.com","city":"Movico","state":"MT"}** */String sourceAsString = searchHit.getSourceAsString();System.out.println(":"+sourceAsString);Account account = JSON.parseObject(sourceAsString, Account.class);System.out.println("account: "+account);}//获取本次检索拿到的聚合信息//拿到所有的聚合根数据Aggregations aggregations = searchResponse.getAggregations();//将聚合信息转换为list集合来进行遍历for (Aggregation aggregation : aggregations.asList()) {System.out.println("####"+aggregation+" | "+aggregation.getName()+" | "+aggregation.getMetaData());/*** ####org.elasticsearch.search.aggregations.metrics.ParsedAvg@4872669f | balanceAvg | null* ####org.elasticsearch.search.aggregations.bucket.terms.ParsedLongTerms@483f286e | ageByGroup | null* 备注:这种方式拿不到具体的聚合数据,要获取对应的聚合数据需要将类型Aggregation强转为对应的子类型,不同的聚合子类型的聚合数据名称不同,* 所以用循环不好处理* */}//其实就是ES自定义了一套jsonBean对象,用户将响应数据转换为对应的对象来获取数据//获取响应的第一个聚合数据Terms ageByGroup = (Terms)aggregations.get("ageByGroup");//对年龄的值分布聚合响应的是Bucket的list集合for (Terms.Bucket bucket : ageByGroup.getBuckets()) {//获取bucket中的key属性,对应属性值分布的每个值和对应值下的文档数量String keyAsString = bucket.getKeyAsString();System.out.println("年龄:"+keyAsString+";记录数:"+bucket.getDocCount());}//获取第二个聚合数据Avg balanceAvg = (Avg) aggregations.get("balanceAvg");System.out.println("平均薪资:"+balanceAvg.getValue());/*** 聚合结果* 年龄:38;记录数:2* 年龄:28;记录数:1* 年龄:32;记录数:1* 平均薪资:25208.0* *//*** ES的对应响应内容* 名字实际上还是ageByGroup和balanceAvg,井号前面的是聚合类型,这个聚合类型是ES官方方便自己添加的,从aggregations中获取用户要的聚合数据* 使用自定义聚合名称即可* "aggregations": {* "avg#balanceAvg": {* "value": 25208.0* },* "lterms#ageByGroup": {* "doc_count_error_upper_bound": 0,* "sum_other_doc_count": 0,* "buckets": [{* "key": 38,* "doc_count": 2* }, {* "key": 28,* "doc_count": 1* }, {* "key": 32,* "doc_count": 1* }]* }* }* }* */}/*** Auto-generated: 2024-05-29 0:43:57* @描述 根据ES返回的结果使用Json工具bejson生成的JavaBean对象,以供测试程序使用,使用Lombok来生成getter和setter以及toString方法* 注意fastjson只能创建静态的内部类实例* @author bejson.com (i@bejson.com)* @website http://www.bejson.com/java2pojo/*/static class Account {private int account_number;private int balance;private String firstname;private String lastname;private int age;private String gender;private String address;private String employer;private String email;private String city;private String state;}}
must函数用法
示例代码1️⃣
请求参数
http://localhost:12000/list.html?keyword=华为&catelog3Id=225&attrs=11_海思芯片:Apple芯片&attrs=12_HUAWEI Kirin 980:M1这种方式也可以使用在要求满足每一种属性可能的属性值条件的场景,这个方式也是可用的;经过验证这种方式不能用啊,这个语句很神奇啊,must下只有任意一个bool语句都能正常检索,但是must下同时有这两个bool会直接什么都查不出来啊,而且看起来逻辑也是对的,这是框架底层的原因,不要深究,直接用第四种
xxxxxxxxxxif (param.getAttrs() != null && param.getAttrs().size()>0) {//封装属性的query语句BoolQueryBuilder nestedBoolQueryBuilder = QueryBuilders.boolQuery();for (String attr:param.getAttrs()) {//对属性进行处理,属性信息格式为attrs=属性id1_属性值1:属性值2String[] attrObject = attr.split("_");String[] attrValue = attrObject[1].split(":");nestedBoolQueryBuilder.must(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("attrs.attrId",attrObject[0])).must(QueryBuilders.termsQuery("attrs.attrValue",attrValue)));}boolQueryBuilder.filter(QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None));}对应DSL
可以看到,同一个
QueryBuilders.boolQuery()不论调用多少个must(),都是放在一个"must"语句中
xxxxxxxxxx{"filter": [{"term": {"catelogId": {"value": 225,"boost": 1}}},{"nested": {"query": {"bool": {"must": [{"bool": {"must": [{"term": {"attrs.attrId": {"value": "11","boost": 1}}},{"terms": {"attrs.attrValue": ["海思芯片","Apple芯片"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},{"bool": {"must": [{"term": {"attrs.attrId": {"value": "12","boost": 1}}},{"terms": {"attrs.attrValue": ["HUAWEI Kirin 980","M1"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}}]}
示例代码2️⃣
请求参数
http://localhost:12000/list.html?keyword=华为&catelog3Id=225&attrs=11_海思芯片:Apple芯片&attrs=12_HUAWEI Kirin 980:M1
xxxxxxxxxxif (param.getAttrs() != null && param.getAttrs().size()>0) {//封装属性的query语句BoolQueryBuilder nestedBoolQueryBuilder = QueryBuilders.boolQuery();for (String attr:param.getAttrs()) {//对属性进行处理,属性信息格式为attrs=属性id1_属性值1:属性值2String[] attrObject = attr.split("_");String[] attrValue = attrObject[1].split(":"); nestedBoolQueryBuilder.must(QueryBuilders.termQuery("attrs.attrId",attrObject[0])).must(QueryBuilders.termsQuery("attrs.attrValue",attrValue));} boolQueryBuilder.filter(QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None));}对应DSL
可以看到,我们希望每个属性的属性id和可能的属性值关联起来,但是由于对同一个
nestedBoolQueryBuilder调用must方法,导致所有的属性id和属性值都关联到一个must中去了
xxxxxxxxxx{"filter": [{"term": {"catelogId": {"value": 225,"boost": 1}}},{"nested": {"query": {"bool": {"must": [{"term": {"attrs.attrId": {"value": "11","boost": 1}}},{"terms": {"attrs.attrValue": ["海思芯片","Apple芯片"],"boost": 1}},{"term": {"attrs.attrId": {"value": "12","boost": 1}}},{"terms": {"attrs.attrValue": ["HUAWEI Kirin 980","M1"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}}]}
示例代码3️⃣
用
bool语句隔开must,用should语句对各个must求或运算请求参数
http://localhost:12000/list.html?keyword=华为&catelog3Id=225&attrs=11_海思芯片:Apple芯片&attrs=12_HUAWEI Kirin 980:M1
xxxxxxxxxxif (param.getAttrs() != null && param.getAttrs().size()>0) {//封装属性的query语句BoolQueryBuilder nestedBoolQueryBuilder = QueryBuilders.boolQuery();for (String attr:param.getAttrs()) {//对属性进行处理,属性信息格式为attrs=属性id1_属性值1:属性值2String[] attrObject = attr.split("_");String[] attrValue = attrObject[1].split(":");nestedBoolQueryBuilder.should(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("attrs.attrId",attrObject[0])).must(QueryBuilders.termsQuery("attrs.attrValue",attrValue)));} boolQueryBuilder.filter(QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None));}对应DSL
这个是能正常使用的,但是如果能有只构建"query"语句不带bool语句的API就更好了
不对啊,这个也不能用啊,因为要求是选出满足对应属性的商品,如果使用或就会导致商品只要满足一个属性就能被展示出来,但是实际上要求商品满足用户选择的所有属性,因此这里的should应该换成must,即第一种情况
xxxxxxxxxx{"filter": [{"term": {"catelogId": {"value": 225,"boost": 1}}},{"nested": {"query": {"bool": {"should": [{"bool": {"must": [{"term": {"attrs.attrId": {"value": "11","boost": 1}}},{"terms": {"attrs.attrValue": ["海思芯片","Apple芯片"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},{"bool": {"must": [{"term": {"attrs.attrId": {"value": "12","boost": 1}}},{"terms": {"attrs.attrValue": ["HUAWEI Kirin 980","M1"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}}],}
示例代码4️⃣
请求参数
http://localhost:12000/list.html?keyword=华为&catelog3Id=225&attrs=11_海思芯片:Apple芯片&attrs=12_HUAWEI Kirin 980:M1
xxxxxxxxxxif (param.getAttrs() != null && param.getAttrs().size()>0) {/*比较一下和上面最终生成的DSL语句的区别,这段是老师的,如果上面的不对再用老师的试一下*/for (String attr:param.getAttrs()) {//封装属性的query语句BoolQueryBuilder nestedBoolQueryBuilder = QueryBuilders.boolQuery();//对属性进行处理,属性信息格式为attrs=属性id1_属性值1:属性值2String[] attrObject = attr.split("_");String[] attrValue = attrObject[1].split(":"); nestedBoolQueryBuilder.must(QueryBuilders.termQuery("attrs.attrId",attrObject[0])).must(QueryBuilders.termsQuery("attrs.attrValue",attrValue)); boolQueryBuilder.filter(QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None));}}对应DSL
这种相当于用
filter语句来过滤掉每一个属性匹配条件,这种也是可以用来处理同时满足所有商品属性
xxxxxxxxxx"filter": [{"term": {"catelogId": {"value": 225,"boost": 1}}},{"nested": {"query": {"bool": {"must": [{"term": {"attrs.attrId": {"value": "11","boost": 1}}},{"terms": {"attrs.attrValue": ["海思芯片","Apple芯片"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}},{"nested": {"query": {"bool": {"must": [{"term": {"attrs.attrId": {"value": "12","boost": 1}}},{"terms": {"attrs.attrValue": ["HUAWEI Kirin 980","M1"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}}]
检索代码示例
通过Java代码自动构建DSL
映射关系
xxxxxxxxxxGET mall_product/_mapping{"mall_product" : {"mappings" : {"properties" : {"attrs" : {"type" : "nested","properties" : {"attrId" : {"type" : "long"},"attrName" : {"type" : "keyword"},"attrValue" : {"type" : "keyword"}}},"brandId" : {"type" : "long"},"brandImg" : {"type" : "keyword"},"brandName" : {"type" : "keyword"},"catelogId" : {"type" : "long"},"catelogName" : {"type" : "keyword"},"hasStock" : {"type" : "boolean"},"hotScore" : {"type" : "long"},"saleCount" : {"type" : "long"},"skuId" : {"type" : "long"},"skuImg" : {"type" : "keyword"},"skuPrice" : {"type" : "keyword"},"skuTitle" : {"type" : "text","analyzer" : "ik_smart"},"spuId" : {"type" : "keyword"}}}}}文档数据
xxxxxxxxxxGET mall_product/_search{"from": 0,"size": 12,"query": {"match_all": {}}}#响应数据{"took":0,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":12,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"mall_product","_type":"_doc","_id":"5","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":5,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice":5699.0,"skuTitle":"华为 HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"6","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":true,"hotScore":0,"saleCount":0,"skuId":6,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice":6299.0,"skuTitle":"华为 HUAWEI Mate60 Pro 星河银 256G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"7","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":true,"hotScore":0,"saleCount":0,"skuId":7,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//41a828f9-1d32-47ab-8254-be59861dc98e_28f296629cca865e.jpg","skuPrice":5699.0,"skuTitle":"华为 HUAWEI Mate60 Pro 亮黑色 128G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"8","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":8,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//41a828f9-1d32-47ab-8254-be59861dc98e_28f296629cca865e.jpg","skuPrice":6299.0,"skuTitle":"华为 HUAWEI Mate60 Pro 亮黑色 256G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"9","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":9,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//14351e50-0f05-44c6-8b5f-ca96781ec61d_1f15cdbcf9e1273c.jpg","skuPrice":5699.0,"skuTitle":"华为 HUAWEI Mate60 Pro 翡冷翠 128G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"10","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":10,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//14351e50-0f05-44c6-8b5f-ca96781ec61d_1f15cdbcf9e1273c.jpg","skuPrice":6299.0,"skuTitle":"华为 HUAWEI Mate60 Pro 翡冷翠 256G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"11","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":11,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice":5699.0,"skuTitle":"华为 HUAWEI Mate60 Pro 罗兰紫 128G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"12","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00;是;否"},{"attrId":11,"attrName":"CPU品牌","attrValue":"海思芯片"}],"brandId":4,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName":"华为","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":12,"skuImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice":6299.0,"skuTitle":"华为 HUAWEI Mate60 Pro 罗兰紫 256G 旗舰新品手机","spuId":5}},{"_index":"mall_product","_type":"_doc","_id":"13","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00"},{"attrId":11,"attrName":"CPU品牌","attrValue":"Apple芯片"}],"brandId":7,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/52b9cc92-6df9-427a-8fcc-c94c413b3e94_apple.png","brandName":"Apple","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":13,"skuPrice":5000.0,"skuTitle":"Apple XR 红 128G","spuId":6}},{"_index":"mall_product","_type":"_doc","_id":"14","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00"},{"attrId":11,"attrName":"CPU品牌","attrValue":"Apple芯片"}],"brandId":7,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/52b9cc92-6df9-427a-8fcc-c94c413b3e94_apple.png","brandName":"Apple","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":14,"skuPrice":6000.0,"skuTitle":"Apple XR 红 256G","spuId":6}},{"_index":"mall_product","_type":"_doc","_id":"15","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00"},{"attrId":11,"attrName":"CPU品牌","attrValue":"Apple芯片"}],"brandId":7,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/52b9cc92-6df9-427a-8fcc-c94c413b3e94_apple.png","brandName":"Apple","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":15,"skuPrice":5000.0,"skuTitle":"Apple XR 黑 128G","spuId":6}},{"_index":"mall_product","_type":"_doc","_id":"16","_score":1.0,"_source":{"attrs":[{"attrId":3,"attrName":"入网型号","attrValue":"LIO-AL00"},{"attrId":11,"attrName":"CPU品牌","attrValue":"Apple芯片"}],"brandId":7,"brandImg":"https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/52b9cc92-6df9-427a-8fcc-c94c413b3e94_apple.png","brandName":"Apple","catelogId":225,"catelogName":"手机","hasStock":false,"hotScore":0,"saleCount":0,"skuId":16,"skuPrice":6000.0,"skuTitle":"Apple XR 黑 256G","spuId":6}}]}}检索逻辑
检索商品名称包含指定关键字、商品分类id为指定值、品牌id为指定值列表、商品属性为指定值且价格范围在指定范围的所有商品记录并按照价格降序排列,对查询到的所有商品记录聚合分析出包含的所有品牌id、品牌名、品牌商标;商品分类id、商品分类名称;所有属性id、属性名称和对应属性id下的全部可能存在的属性值,高亮检索关键字、记录分页
检索方法的基本结构
控制器方法
xxxxxxxxxxpublic class ESSearchController {private ESSearchService esSearchService;/*** @param param* @param model* @return {@link String }* @描述 注意请求路径的参数会自动封装到请求参数列表中,无需添加额外注解* @author Earl* @version 1.0.0* @创建日期 2024/09/06* @since 1.0.0*/("/list.html")public String getSearchPage(SearchParam param, Model model){//1. 根据请求参数去构建DSL语句去ES中检索对应商品SkuSearchResult result = esSearchService.searchProduct(param);//2. 将检索结果添加到ModelAndView中准备渲染检索页面model.addAttribute("searchResult",result);return "list";}}检索方法大结构
整体结构为构建一个
SearchRequest封装检索DSL语句,用RestHighLevelClient使用SearchRequest发送请求执行检索并返回检索结果,将检索结果封装成我们自定义的响应对象构建检索请求对象即构建检索DSL比较复杂,单独抽取成
buildSearchRequest()方法,这方法有100行根据检索结果构建响应对象的过程也比较复杂,单独抽取成
buildSearchResponse()方法
xxxxxxxxxx(topic = "es.search")public class ESSearchServiceImpl implements ESSearchService {private RestHighLevelClient esRESTClient;public SkuSearchResult searchProduct(SearchParam param) {SkuSearchResult result = null;//1. 准备检索请求,但是检索请求太过复杂,我们希望调用一个私有方法来专门构建请求,直接返回检索请求//SearchRequest searchRequest = new SearchRequest();SearchRequest searchRequest = buildSearchRequest(param);try {//2. 通过检索请求执行检索SearchResponse response = esRESTClient.search(searchRequest, MallElasticSearchConfig.COMMON_OPTIONS);//3. 将检索结果封装成我们自定义的响应对象result = buildSearchResponse(response);} catch (IOException e) {e.printStackTrace();}return result;}}DSL检索根据逻辑手动构建的语句
注意这个
"skuTitle": "华为"可以写成"skuTitle": "华为,apple"同时检索文档skuTitle属性为华为或者apple的文档记录,只要包含华为或者包含`Apple的文档记录都可以被检索到
xxxxxxxxxx{"@WEB API": "GET mall_product/_search","query": {"bool": {"must": [{"match": {"skuTitle": "华为"}}],"filter": [{"term": {"catelogId": 225}},{"terms": {"brandId": ["4","1","9"]}},{"nested": {"path": "attrs","query": {"bool": {"must": [{"term": {"attrs.attrId": "11"}},{"terms": {"attrs.attrValue": ["海思芯片","以官网信息为准"]}}]}}}},{"range": {"skuPrice": {"gte": 0,"lte": 6000}}},{"term": {"hasStock": true}}]}},"aggs": {"brand_agg": {"terms": {"field": "brandId","size": 10},"aggs": {"brand_name_agg": {"terms": {"field": "brandName","size": 10}},"brand_img_agg": {"terms": {"field": "brandImg","size": 10}}}},"catelog_agg": {"terms": {"field": "catelogId","size": 10},"aggs": {"catelog_name_agg": {"terms": {"field": "catelogName","size": 10}}}},"attrs_agg": {"nested": {"path": "attrs"},"aggs": {"attrs_id_agg": {"terms": {"field": "attrs.attrId","size": 10},"aggs": {"attr_name_agg": {"terms": {"field": "attrs.attrName","size": 10}},"attr_value_agg": {"terms": {"field": "attrs.attrValue","size": 10}}}}}}},"sort": {"skuPrice": {"order": "desc"}},"from": 0,"size": 20,"highlight": {"fields": {"skuTitle": {}},"pre_tags": "<b style='color:red'>","post_tags": "</b>"}}请求路径
http://localhost:12000/list.html?keyword=华为&catelog3Id=225&attrs=11_海思芯片:Apple芯片&attrs=3_LIO-AL00;是;否:LIO-AL00&skuPrice=12_6000构建检索DSL的
buildSearchRequest()方法检索语句的构建需要通过对象
SearchSourceBuilder进行,通过searchRequest.source(searchSourceBuilder)来封装检索条件SearchRequest对象有一个双参构造方法public SearchRequest(String[] indices, SearchSourceBuilder source),第一个参数是指定从哪些索引中检索数据,第二个参数是构建DSL语句的SearchSourceBuilder对象
[基本框架]
封装查询条件需要使用
QueryBuilders对象、封装聚合分析语句需要使用AggregationBuilders,并且通过SearchSourceBuilder对象的query、aggregation方法来分别封装这些builders
[构建query语句]
我这里的
nested语句还是按照上面的DSL语句处理的,雷神的处理方式是在filter语句中创建多个nested语句,导致处理方式变化的原因是nestedBoolQueryBuilder.must()方法无法传参多个QueryBuilders,但是又需要同时包含term语句和terms语句,让term和terms处于不同的must中就剥离了属性id和属性值的与运算;我这里的处理方式是在must中再构建一个query语句,在query语句中,实际上我的处理方法是不行的,细节看must语句的分析通过
searchSourceBuilder.query(boolQueryBuilder)在构建好boolQueryBuilder后再构建最外层的query语句通过
QueryBuilders.matchQuery("skuTitle",param.getKeyword())来构建在属性skuTitle中模糊匹配的关键字keyword的match语句通过
QueryBuilders.termQuery("catelogId",param.getCatelog3Id())构建精确匹配非text属性catelogId的term语句通过
QueryBuilders.termsQuery("brandId",param.getBrandIds())来构建一个属性brandId的多值匹配的terms语句,这个暂时也认为是非text精确匹配通过
QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None)来构建nested类型属性attrs的nested匹配语句,nestedBoolQueryBuilder实际就是QueryBuilders.boolQuery(),ScoreMode.None是当前nested类型匹配不计入文档评分,返回通过
QueryBuilders.boolQuery()构建bool语句,返回BoolQueryBuilder,通过该对象的上述方法构建或关系的查询匹配语句通过
QueryBuilders.rangeQuery("skuPrice")构建针对属性skuPrice的range匹配范围语句,通过返回对象的gte方法指定范围区间低值,通过返回对象的lte方法指定范围区间高值,不指定高低值默认为null,分别对应0和无穷大通过
boolQueryBuilder.filter(QueryBuilder queryBuilder)来在同一个filter语句中构建多个子查询语句,这里的queryBuilder一般通过上述方法获取通过
boolQueryBuilder.must(QueryBuilder queryBuilder)来在bool语句下构建must语句,must语句中一般使用term或terms语句,同一个boolQueryBuilder对象多次调用must方法是在同一个must语句中添加子查询语句,这些子查询语句都必须同时满足的记录才会被检索出来
[构建排序、分页、高亮]
排序用
searchSourceBuilder.sort(String path,SortOrder order)来设置path属性的排序规则分页用
searchSourceBuilder.from(int fromIndex)设置首条记录的位置,用searchSourceBuilder.size(int size)设置每页记录数,即使没有设置分页参数也要设置默认分页数据让当前页码pageNum为第一页,定义一个每页商品记录数size常量;当用户指定页码后当前页pageNum为用户指定页码,DSL语句中的from=(pageNum-1)*size,size就使用设置的常量即可,这里size设置为2是商品数据量较小,方便查看分页效果高亮只有有
keyword对商品名称进行模糊匹配的时候才能用,通过searchSourceBuilder.highlighter(HighlightBuilder highlightBuilder)传参HighlightBuilder对象,通过HighlightBuilder.field(String field)指定对哪个属性的匹配关键字进行高亮,通过HighlightBuilder.preTags(String preTag)指定高亮标签前缀,通过HighlightBuilder.postTags(String postTag)后缀
[聚合分析]
聚合分析语句的子语句比如term语句、terms语句都由
AggregationBuilders构建,aggregationBuilders.terms(String aggName)是构建自定义聚合aggName下的terms语句,对应的field属性和size属性通过对应的同名方法指定,注意聚合没有term语句[因为term是单属性值匹配,不适合这种对属性值分组分析场景]termsAggregationBuilder.subAggregation(AggregationBuilder aggregationBuilder)是构建子聚合,子聚合的具体内容一般也是通过aggregationBuilders.terms(String aggName)通过terms来做聚合searchSourceBuilder.aggregation(AggregationBuilder aggregationBuilder)可以调用多个将多个聚合操作放在DSL语句中的同一个aggregations语句下
xxxxxxxxxx/*** @return {@link SearchRequest }* @描述 通过用户检索传参构建检索请求* 功能包括: 模糊匹配关键字、按照属性值、商品分类、商品品牌、价格区间、库存对检索结果进行过滤,对检索结果进行排序* 、分页、对商品名称中的检索关键字进行高亮,对所有检索结果进行聚合分析* @author Earl* @version 1.0.0* @创建日期 2024/09/06* @since 1.0.0* @param param*/private SearchRequest buildSearchRequest(SearchParam param) {SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//功能包括: 模糊匹配关键字、按照属性值、商品分类、商品品牌、价格区间、库存对检索结果进行过滤,对检索结果进行排序//、分页、对商品名称中的检索关键字进行高亮,对所有检索结果进行聚合分析//1. 构建query查询语句BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();//1.1 如果检索关键字不为空,将match_all语句封装到must语句中,将must语句封装到query语句中if (!StringUtils.isEmpty(param.getKeyword())) {boolQueryBuilder.must(QueryBuilders.matchQuery("skuTitle",param.getKeyword()));}//1.2 如果三级商品分类id不为空,将term语句封装到filter语句中,将filter语句封装到query语句中if (param.getCatelog3Id() != null) {boolQueryBuilder.filter(QueryBuilders.termQuery("catelogId",param.getCatelog3Id()));}//1.3 如果品牌id不为空且元素个数大于0,将terms语句封装到filter语句中,将filter语句封装到query语句中if (param.getBrandIds() != null && param.getBrandIds().size()>0) {boolQueryBuilder.filter(QueryBuilders.termsQuery("brandId",param.getBrandIds()));}//1.4 如果属性不为空且元素个数大于0,将term和terms语句封装到must语句中,将must语句封装到bool语句中,将bool语句封装到nested语句中,// 将nested语句封装到filter语句中,将filter语句封装到query语句中if (param.getAttrs() != null && param.getAttrs().size()>0) {/*比较一下和上面最终生成的DSL语句的区别,这段是老师的,如果上面的不对再用老师的试一下*/for (String attr:param.getAttrs()) {//封装属性的query语句BoolQueryBuilder nestedBoolQueryBuilder = QueryBuilders.boolQuery();//对属性进行处理,属性信息格式为attrs=属性id1_属性值1:属性值2String[] attrObject = attr.split("_");String[] attrValue = attrObject[1].split(":");nestedBoolQueryBuilder.must(QueryBuilders.termQuery("attrs.attrId",attrObject[0])).must(QueryBuilders.termsQuery("attrs.attrValue",attrValue));boolQueryBuilder.filter(QueryBuilders.nestedQuery("attrs",nestedBoolQueryBuilder,ScoreMode.None));}}//1.5 如果是否显示有无货不为空,将term语句封装到filter语句中,将filter语句封装到query语句中if (param.getHasStock() != null) {boolQueryBuilder.filter(QueryBuilders.termQuery("hasStock",param.getHasStock()==1));}//1.6 如果价格区间不为空,将range语句封装到filter中,将filter语句封装到query语句中if(!StringUtils.isEmpty(param.getSkuPrice())){String skuPrice = param.getSkuPrice().trim();String[] skuPriceArr = skuPrice.split("_");if(skuPriceArr.length==1){boolQueryBuilder.filter(QueryBuilders.rangeQuery("skuPrice").gte(skuPriceArr[0]).lte(Long.MAX_VALUE));}else {boolQueryBuilder.filter(QueryBuilders.rangeQuery("skuPrice").gte("".equals(skuPriceArr[0])?0:skuPriceArr[0]).lte(skuPriceArr[1]));}}//构建query语句sourceBuilder.query(boolQueryBuilder);//2. 排序、分页、高亮//2.1 排序if (!StringUtils.isEmpty(param.getSort())) {String[] sortPolicy = param.getSort().split("_");sourceBuilder.sort(sortPolicy[0],"asc".equalsIgnoreCase(sortPolicy[1])? SortOrder.ASC:SortOrder.DESC);}//2.2 分页//from=(pageNum-1)*size,分页即使用户不指定也要有默认设置sourceBuilder.from((param.getPageNum()-1)*EsConstant.PRODUCT_PAGE_SIZE);sourceBuilder.size(EsConstant.PRODUCT_PAGE_SIZE);//2.3 高亮if (!StringUtils.isEmpty(param.getKeyword())) {HighlightBuilder highlightBuilder = new HighlightBuilder().field("skuTitle").preTags("<b style='color:red'>").postTags("</b>");sourceBuilder.highlighter(highlightBuilder);}//3. 聚合分析,对查询到的所有商品记录聚合分析出包含的所有品牌id、品牌名、品牌商标;// 商品分类id、商品分类名称;// 所有属性id、属性名称和对应属性id下的全部可能存在的属性值//3.1 聚合分析出所有商品记录的所有品牌id、品牌名、品牌商标TermsAggregationBuilder brand_agg = AggregationBuilders.terms("brand_agg");brand_agg.field("brandId").size(20);//子聚合得到对应品牌id的名字和图标brand_agg.subAggregation(AggregationBuilders.terms("brand_name_agg").field("brandName").size(1));brand_agg.subAggregation(AggregationBuilders.terms("brand_img_agg").field("brandImg").size(1));sourceBuilder.aggregation(brand_agg);//3.2 聚合分析出所有商品记录的所有商品分类id和对应的商品分类名称TermsAggregationBuilder catelog_agg = AggregationBuilders.terms("catelog_agg");catelog_agg.field("catelogId").size(20);//子聚合得到对应商品分类的名字catelog_agg.subAggregation(AggregationBuilders.terms("catelog_name_agg").field("catelogName").size(1));sourceBuilder.aggregation(catelog_agg);//3.3 聚合分析所有商品记录的所有属性值和对应的所有属性值//准备属性聚合对象attrs_agg采用NestedAggregationBuilderNestedAggregationBuilder attrs_agg = AggregationBuilders.nested("attrs_agg", "attrs");//属性聚合对象对属性id子聚合采用TermsAggregationBuilderTermsAggregationBuilder attrs_id_agg = AggregationBuilders.terms("attrs_id_agg").field("attrs.attrId").size(50);//属性id聚合对象对属性名字和可能属性子聚合采用TermsAggregationBuilderattrs_id_agg.subAggregation(AggregationBuilders.terms("attr_name_agg").field("attrs.attrName").size(1));attrs_id_agg.subAggregation(AggregationBuilders.terms("attr_value_agg").field("attrs.attrValue").size(50));//让NestedAggregationBuilder和TermsAggregationBuilder形成父子聚合关系attrs_agg.subAggregation(attrs_id_agg);//把属性聚合加入到DSL检索语句中sourceBuilder.aggregation(attrs_agg);//打印SearchSourceBuilder即DSL语句System.out.println("构建的DSL语句:"+sourceBuilder);SearchRequest searchRequest = new SearchRequest(new String[]{EsConstant.PRODUCT_INDEX}, sourceBuilder);return searchRequest;}对应代码构建的DSL语句
xxxxxxxxxxGET mall_product/_search{"from": 0,"size": 2,"query": {"bool": {"must": [{"match": {"skuTitle": {"query": "华为","operator": "OR","prefix_length": 0,"max_expansions": 50,"fuzzy_transpositions": true,"lenient": false,"zero_terms_query": "NONE","auto_generate_synonyms_phrase_query": true,"boost": 1}}}],"filter": [{"term": {"catelogId": {"value": 225,"boost": 1}}},{"nested": {"query": {"bool": {"must": [{"term": {"attrs.attrId": {"value": "11","boost": 1}}},{"terms": {"attrs.attrValue": ["海思芯片","Apple芯片"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}},{"nested": {"query": {"bool": {"must": [{"term": {"attrs.attrId": {"value": "3","boost": 1}}},{"terms": {"attrs.attrValue": ["LIO-AL00;是;否","LIO-AL00"],"boost": 1}}],"adjust_pure_negative": true,"boost": 1}},"path": "attrs","ignore_unmapped": false,"score_mode": "none","boost": 1}},{"range": {"skuPrice": {"from": "12","to": "6000","include_lower": true,"include_upper": true,"boost": 1}}}],"adjust_pure_negative": true,"boost": 1}},"aggregations": {"brand_agg": {"terms": {"field": "brandId","size": 20,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]},"aggregations": {"brand_name_agg": {"terms": {"field": "brandName","size": 1,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]}},"brand_img_agg": {"terms": {"field": "brandImg","size": 1,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]}}}},"catelog_agg": {"terms": {"field": "catelogId","size": 20,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]},"aggregations": {"catelog_name_agg": {"terms": {"field": "catelogName","size": 1,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]}}}},"attrs_agg": {"nested": {"path": "attrs"},"aggregations": {"attrs_id_agg": {"terms": {"field": "attrs.attrId","size": 50,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]},"aggregations": {"attr_name_agg": {"terms": {"field": "attrs.attrName","size": 1,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]}},"attr_value_agg": {"terms": {"field": "attrs.attrValue","size": 50,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]}}}}}}},"highlight": {"pre_tags": ["<b style='color:red'>"],"post_tags": ["</b>"],"fields": {"skuTitle": {}}}}Kibana使用自动构建语句响应的检索结果
xxxxxxxxxx{"took" : 7,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 0.5949395,"hits" : [{"_index" : "mall_product","_type" : "_doc","_id" : "5","_score" : 0.5949395,"_source" : {"attrs" : [{"attrId" : 3,"attrName" : "入网型号","attrValue" : "LIO-AL00;是;否"},{"attrId" : 11,"attrName" : "CPU品牌","attrValue" : "海思芯片"}],"brandId" : 4,"brandImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName" : "华为","catelogId" : 225,"catelogName" : "手机","hasStock" : false,"hotScore" : 0,"saleCount" : 0,"skuId" : 5,"skuImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice" : 5699.0,"skuTitle" : "华为 HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机","spuId" : 5},"highlight" : {"skuTitle" : ["<b style='color:red'>华为</b> HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机"]}},{"_index" : "mall_product","_type" : "_doc","_id" : "7","_score" : 0.5949395,"_source" : {"attrs" : [{"attrId" : 3,"attrName" : "入网型号","attrValue" : "LIO-AL00;是;否"},{"attrId" : 11,"attrName" : "CPU品牌","attrValue" : "海思芯片"}],"brandId" : 4,"brandImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName" : "华为","catelogId" : 225,"catelogName" : "手机","hasStock" : true,"hotScore" : 0,"saleCount" : 0,"skuId" : 7,"skuImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//41a828f9-1d32-47ab-8254-be59861dc98e_28f296629cca865e.jpg","skuPrice" : 5699.0,"skuTitle" : "华为 HUAWEI Mate60 Pro 亮黑色 128G 旗舰新品手机","spuId" : 5},"highlight" : {"skuTitle" : ["<b style='color:red'>华为</b> HUAWEI Mate60 Pro 亮黑色 128G 旗舰新品手机"]}}]},"aggregations" : {"attrs_agg" : {"doc_count" : 8,"attrs_id_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 3,"doc_count" : 4,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "入网型号","doc_count" : 4}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "LIO-AL00;是;否","doc_count" : 4}]}},{"key" : 11,"doc_count" : 4,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "CPU品牌","doc_count" : 4}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "海思芯片","doc_count" : 4}]}}]}},"catelog_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 225,"doc_count" : 4,"catelog_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "手机","doc_count" : 4}]}}]},"brand_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 4,"doc_count" : 4,"brand_img_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","doc_count" : 4}]},"brand_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "华为","doc_count" : 4}]}}]}}}
检索结果封装示例
自定义方法
buildSearchResponse(SearchResponse response)封装检索结果为我们自定义响应对象业务逻辑
封装所有查询到的当前页的商品数据、
封装当前商品涉及到的所有属性聚合信息、品牌信息、商品分类信息
封装分页信息-当前页码和总记录数
检索响应结果对象的结构
Java High Level REST Client API的检索方法SearchResponse response = esRESTClient.search(searchRequest, MallElasticSearchConfig.COMMON_OPTIONS);检索响应结果对象的类型是SearchResponse对象,该对象中的internalResponse属性中封装了全部检索数据searchResponse.internalResponse.hits中封装了检索命中的记录,hits内部的属性和检索结果的结构是完全相同的总记录数
hits.getTotalHits().value获取命中记录的总记录数总页码需要自己根据总记录数和每页记录数自己运算得到,可以通过算法
总页码=(int)(总记录数-1)/每页记录数+1进行计算当前页码需要使用请求参数中的页码数据
所有记录通过
hits.getHits()获取的是每一条记录的元数据+文档信息,其中的_source属性才是真正的文档数据,hits.getHits()获取的列表其中的每个元素hit可以通过hit.getSourceAsString()可以获取到json格式的文档数据字符串,通过fastjson转换为商品对象并加入list集合
xxxxxxxxxx"hits": {"total": {"value": 4,"relation": "eq"},"max_score": 0.5949395,"hits": [{"_index": "mall_product","_type": "_doc","_id": "5","_score": 0.5949395,"_source": {"attrs": [{"attrId": 3,"attrName": "入网型号","attrValue": "LIO-AL00;是;否"},{"attrId": 11,"attrName": "CPU品牌","attrValue": "海思芯片"}],"brandId": 4,"brandImg": "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName": "华为","catelogId": 225,"catelogName": "手机","hasStock": false,"hotScore": 0,"saleCount": 0,"skuId": 5,"skuImg": "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice": 5699.0,"skuTitle": "华为 HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机","spuId": 5},"highlight": {"skuTitle": ["<b style='color:red'>华为</b> HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机"]}},{}]}searchResponse.internalResponse.aggregations中封装了聚合分析的结果,aggregations内部的属性和检索结果的结构是完全相同的searchResponse.internalResponse.aggregations.aggregations这个ArrayList中封装了多个聚合结果,每个元素都是一个单独的聚合结果,聚合结构元素的类型不同,一般有ParsedLongTerms、ParsedNested、ParseStringTerms通过
searchResponse.getAggregations().get(String customAggregationName)可以获取对应聚合名字的聚合分析结果,注意这里的返回结果类型使用了多态,用了父类型Aggregation类型,但是我们需要子类实现来调用对应的子类方法,因为不同子实现类的聚合结果层级结构不同,父类型方法不够用注意Aggregation子实现类贼多,而且层级复杂,一般要通过打断点观察一下返回聚合结果的具体类型才能确定子实现类的类型
通过
aggregation.getBuckets()获取bucket中的聚合数据ArrayList数组,对数组中的每一个bucket元素通过bucket.getKeyAsString()获取到字符串类型的聚合分组属性值,通过bucket.getKeyAsNumber()获取到long类型的聚合分组属性值,通过bucket.getAggregations().get(String customAggregationName)获取到对应名字的子聚合,子聚合也通过上述方法获取到字符串类型的聚合分组属性值,如果子聚合确定只有一个属性值就不用对子聚合的bucket进行遍历了,可以直接通过aggregation.getBuckets().get(0)来获取bucket的key属性值❓:注意
Aggregation无法调用aggregation.getBuckets(),必须强转为子类才能调用该方法获取到聚合结果,这难道不是设计缺陷吗
xxxxxxxxxx"aggregations" : {"attrs_agg" : {"doc_count" : 8,"attrs_id_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 3,"doc_count" : 4,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "入网型号","doc_count" : 4}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "LIO-AL00;是;否","doc_count" : 4}]}},{"key" : 11,"doc_count" : 4,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "CPU品牌","doc_count" : 4}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "海思芯片","doc_count" : 4}]}}]}},"catelog_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 225,"doc_count" : 4,"catelog_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "手机","doc_count" : 4}]}}]},"brand_agg" : {}}
检索结果封装代码
这种方式封装的商品标题匹配的检索关键字并没有被高亮,还需要对标题进行单独封装来保证商品名称检索关键字的高亮,要高亮还需要满足检索参数中有用户输入的检索关键字才会封装高亮数据,高亮数据在与source平级的hightlight属性中封装,直接替换掉source中对应的字段即可
xxxxxxxxxx/*** @return {@link SkuSearchResult }* @描述 将检索结果封装成我们自定义的响应对象* 封装检索记录、封装聚合结果,所有记录涉及的属性和属性值、所有记录涉及的品牌、所有记录涉及的商品分类* @author Earl* @version 1.0.0* @创建日期 2024/09/06* @since 1.0.0* @param response* @param pageNum*/private SkuSearchResult buildSearchResponse(SearchResponse response, Integer pageNum) {//准备响应结果的容器SkuSearchResult result = new SkuSearchResult();//1. 封装所有检索记录SearchHit[] hits = response.getHits().getHits();ArrayList<Product> searchProducts = new ArrayList<>(hits.length);for (SearchHit hit : hits) {Product product = JSON.parseObject(hit.getSourceAsString(), Product.class);searchProducts.add(product);}result.setProducts(searchProducts);//2. 封装所有记录涉及到的商品品牌ArrayList<SkuSearchResult.BrandVo> brands = new ArrayList<>();//必须强转为子类才能调用getBuckets方法ParsedLongTerms brand_agg = (ParsedLongTerms) response.getAggregations().get("brand_agg");//2.1 获取商品品牌的idfor (Terms.Bucket bucket : brand_agg.getBuckets()) {SkuSearchResult.BrandVo brand = new SkuSearchResult.BrandVo();brand.setBrandId(Long.parseLong(bucket.getKeyAsString()));//2.2 获取商品品牌的图片ParsedStringTerms brand_img_agg = (ParsedStringTerms) bucket.getAggregations().get("brand_img_agg");brand.setBrandImg(brand_img_agg.getBuckets().get(0).getKeyAsString());//2.3 获取商品品牌的名字ParsedStringTerms brand_name_agg = (ParsedStringTerms) bucket.getAggregations().get("brand_name_agg");brand.setBrandName(brand_name_agg.getBuckets().get(0).getKeyAsString());brands.add(brand);}result.setBrands(brands);//3. 封装所有记录涉及到的商品种类ArrayList<SkuSearchResult.CatelogVo> catelogs = new ArrayList<>();ParsedLongTerms catelog_agg = (ParsedLongTerms) response.getAggregations().get("catelog_agg");//3.1 获取商品分类的idfor (Terms.Bucket bucket : catelog_agg.getBuckets()) {SkuSearchResult.CatelogVo catelog = new SkuSearchResult.CatelogVo();catelog.setCatelogId(Long.parseLong(bucket.getKeyAsString()));//3.2 获取商品分类的名字ParsedStringTerms catelog_name_agg = (ParsedStringTerms) bucket.getAggregations().get("catelog_name_agg");catelog.setCatelogName(catelog_name_agg.getBuckets().get(0).getKeyAsString());catelogs.add(catelog);}result.setCatelogs(catelogs);//4. 封装所有记录涉及到的属性种类ArrayList<SkuSearchResult.AttrVo> attrs = new ArrayList<>();ParsedNested attrs_agg = (ParsedNested) response.getAggregations().get("attrs_agg");ParsedLongTerms attrs_id_agg = (ParsedLongTerms) attrs_agg.getAggregations().get("attrs_id_agg");//4.1 获取商品属性的idfor (Terms.Bucket bucket : attrs_id_agg.getBuckets()) {SkuSearchResult.AttrVo attr = new SkuSearchResult.AttrVo();attr.setAttrId(Long.parseLong(bucket.getKeyAsString()));//4.2 获取商品属性的名字ParsedStringTerms attr_name_agg = (ParsedStringTerms) bucket.getAggregations().get("attr_name_agg");attr.setAttrName(attr_name_agg.getBuckets().get(0).getKeyAsString());//4.3 获取商品属性所有可能的属性值ArrayList<String> attrValues = new ArrayList<>();ParsedStringTerms attr_value_agg = (ParsedStringTerms) bucket.getAggregations().get("attr_value_agg");attr.setAttrValue(attr_value_agg.getBuckets().stream().map(item -> item.getKeyAsString()).collect(Collectors.toList()));attrs.add(attr);}result.setAttrs(attrs);//5. 封装分页信息//5.1 封装总记录数long total = response.getHits().getTotalHits().value;result.setTotal(total);//5.2 封装当前页码result.setPageNum(pageNum);//5.3 封装总页码数result.setTotalPages(((total - 1) / EsConstant.PRODUCT_PAGE_SIZE)+1);return result;}带高亮关键字的检索结果封装代码
xxxxxxxxxx/*** @return {@link SkuSearchResult }* @描述 将检索结果封装成我们自定义的响应对象* 封装检索记录、封装聚合结果,所有记录涉及的属性和属性值、所有记录涉及的品牌、所有记录涉及的商品分类* @author Earl* @version 1.0.0* @创建日期 2024/09/06* @since 1.0.0* @param response* @param pageNum* @param keyword*/private SkuSearchResult buildSearchResponse(SearchResponse response, Integer pageNum, String keyword) {//准备响应结果的容器SkuSearchResult result = new SkuSearchResult();//1. 封装所有检索记录SearchHit[] hits = response.getHits().getHits();ArrayList<Product> searchProducts = new ArrayList<>(hits.length);for (SearchHit hit : hits) {Product product = JSON.parseObject(hit.getSourceAsString(), Product.class);//高亮字段信息存在hits.hits的highlightFields属性中的value属性的fragment数组中if(!StringUtils.isEmpty(keyword)){product.setSkuTitle(hit.getHighlightFields().get("skuTitle").getFragments()[0].string());}searchProducts.add(product);}result.setProducts(searchProducts);//2. 封装所有记录涉及到的商品品牌Aggregations aggregations = response.getAggregations();ArrayList<SkuSearchResult.BrandVo> brands = new ArrayList<>();//必须强转为子类才能调用getBuckets方法ParsedLongTerms brand_agg = (ParsedLongTerms) aggregations.get("brand_agg");//2.1 获取商品品牌的idfor (Terms.Bucket bucket : brand_agg.getBuckets()) {SkuSearchResult.BrandVo brand = new SkuSearchResult.BrandVo();brand.setBrandId(Long.parseLong(bucket.getKeyAsString()));//2.2 获取商品品牌的图片ParsedStringTerms brand_img_agg = (ParsedStringTerms) bucket.getAggregations().get("brand_img_agg");brand.setBrandImg(brand_img_agg.getBuckets().get(0).getKeyAsString());//2.3 获取商品品牌的名字ParsedStringTerms brand_name_agg = (ParsedStringTerms) bucket.getAggregations().get("brand_name_agg");brand.setBrandName(brand_name_agg.getBuckets().get(0).getKeyAsString());brands.add(brand);}result.setBrands(brands);//3. 封装所有记录涉及到的商品种类ArrayList<SkuSearchResult.CatelogVo> catelogs = new ArrayList<>();ParsedLongTerms catelog_agg = (ParsedLongTerms) aggregations.get("catelog_agg");//3.1 获取商品分类的idfor (Terms.Bucket bucket : catelog_agg.getBuckets()) {SkuSearchResult.CatelogVo catelog = new SkuSearchResult.CatelogVo();catelog.setCatelogId(Long.parseLong(bucket.getKeyAsString()));//3.2 获取商品分类的名字ParsedStringTerms catelog_name_agg = (ParsedStringTerms) bucket.getAggregations().get("catelog_name_agg");catelog.setCatelogName(catelog_name_agg.getBuckets().get(0).getKeyAsString());catelogs.add(catelog);}result.setCatelogs(catelogs);//4. 封装所有记录涉及到的属性种类ArrayList<SkuSearchResult.AttrVo> attrs = new ArrayList<>();ParsedNested attrs_agg = (ParsedNested) aggregations.get("attrs_agg");ParsedLongTerms attrs_id_agg = (ParsedLongTerms) attrs_agg.getAggregations().get("attrs_id_agg");//4.1 获取商品属性的idfor (Terms.Bucket bucket : attrs_id_agg.getBuckets()) {SkuSearchResult.AttrVo attr = new SkuSearchResult.AttrVo();attr.setAttrId(Long.parseLong(bucket.getKeyAsString()));//4.2 获取商品属性的名字ParsedStringTerms attr_name_agg = (ParsedStringTerms) bucket.getAggregations().get("attr_name_agg");attr.setAttrName(attr_name_agg.getBuckets().get(0).getKeyAsString());//4.3 获取商品属性所有可能的属性值ArrayList<String> attrValues = new ArrayList<>();ParsedStringTerms attr_value_agg = (ParsedStringTerms) bucket.getAggregations().get("attr_value_agg");attr.setAttrValue(attr_value_agg.getBuckets().stream().map(item -> item.getKeyAsString()).collect(Collectors.toList()));attrs.add(attr);}result.setAttrs(attrs);//5. 封装分页信息//5.1 封装总记录数long total = response.getHits().getTotalHits().value;result.setTotal(total);//5.2 封装当前页码result.setPageNum(pageNum);//5.3 封装总页码数result.setTotalPages(((total - 1) / EsConstant.PRODUCT_PAGE_SIZE)+1);return result;}
ES在项目中的应用
ES作为全文检索引擎承担项目中的全文检索功能,如商城中按照商品名称或者商品的sku属性信息来全文检索相关的商品记录
ES还会承担项目中的日志分析检索功能,一些故障需要快速定位,日常运行产生的日志也存在全文检索需求,将日志存储在ES中来对日志做全文检索功能,日志的处理使用ELK技术栈,由LogStash负责收集日志,将搜集的日志存储到ES中,以Kibana作为可视化界面,这部分在运维阶段介绍ELK技术栈
腾讯云ES服务的环境架构
架构说明
服务器、移动设备、或者物联网传感器产生的日志通过Kafka或者LogStash搜集到ES服务器中,通过可视化工具来对日志进行检索和监控
架构图

商品上架
ES做sku全文检索分析
需要将sku商品信息存储在ES服务器上,将sku信息存入ES的过程称为商品上架,只有上架的商品才能在商城界面展示出来,没有上架的商品只能在后台管理系统看见
使用ES做全文检索而不采用mysql的原因是mysql的全文检索功能没有ES的强大,mysql做复杂全文检索的性能远不及ES,ES将数据存储在内存中,性能远高于mysql;其次,ES天然就支持分布式集群,如果当前集群内存不够,直接像集群中添加ES节点即可
由于内存比较贵,虽然商品上架点击的是spu管理中的上架按钮,但是为了节省内存,只向ES中保存商城搜索页面会使用到的数据【商品展示数据和用于检索的数据】,类似于商品图片,细节的sku属性,spu属性等商品详情页面都等拿到商品的sku_id后,商品的完整介绍、全部图片、完整的信息再去数据库直接查
业务逻辑
1️⃣:后台管理界面商品维护菜单下的spu管理中spu列表每条记录有对应的上架按钮,点击上架按钮一方面将商品的
spu_info表中的状态字段publish_status改为上架状态【0表示未上架状态,1表示上架状态】,另一方面对应的商品数据保存至ES服务器中2️⃣:分析需要存储到ES的具体数据
检索词条商品标题和副标题
用户可能按照商品sku的价格区间进行检索
可能按照商品的销量进行排序,以上都属于商品的sku属性
可能直接点击商品分类检索跳转商品页面,这是按照商品分类进行检索,需要保存商品的分类信息
可能直接点击商品的所属品牌,按照品牌进行检索,需要保存商品的品牌信息
可能按照商品额规格属性进行检索,如屏幕尺寸、CPU类型等等,因此还需要保存商品的spu属性
3️⃣:文档数据存储方案
设计1:如果每个商品都设计为如下的文档类型,这种设计的好处是方便检索,但是可能会存在大量的数据冗余,因为同一个spuId下存在大量的sku商品,但是这些商品的spu属性都是相同的,如果有100万个商品,平均每个商品有20个sku,假设每个sku的重复数据为100Byte,需要额外1000000*2KB=2000MB=2GB,一般来说,这个冗余量还是比较好处理,即使是20G的冗余也比较容易处理,加一根内存条就能解决
xxxxxxxxxx{skuId: 1,spuId: 11,skuTitle: 华为XX,price: 998,saleCount: 99,attrs: [{尺寸: 5寸},{CPU: 高通945},{分辨率: 全高清}]}设计2:如果商品设计为下列文档类型,这种方式检索也比较方便,数据也不会出现冗余存储;但是这种方式有一个致命问题,检索条件的spu属性是统计当前检索商品文档对应的所有spu的可能属性动态生成的,意味着比如检索一个品牌如小米,需要检索出商品名字含小米的全部商品,并且查询出所有的spuId,假设1000个商品对应4000个spu,需要单次网络传输传递4000个Long类型的id,每个Long类型数据占8个字节,单次查询spu属性的请求体数据大小为4000*8Byte=32KB,一个请求就会发送超过32KB的数据,如果是10000的并发,每秒内网传输的数据就是320MB的大小,像超大型电商平台百万的并发,内网传输的数据将会变成32GB,这将会造成极大的网络阻塞,而且还没有考虑其他请求的情况下【单是拆分出spu单独检索就会产生的额外开销】,因此考虑第一种冗余设计,以空间换时间
xxxxxxxxxxsku索引{skuId: 1,spuId: 11,xxxxsku相关信息}attr索引{spuId: 11,attrs: [{尺寸: 5寸},{CPU: 高通945},{分辨率: 全高清}]}
4️⃣:商品文档数据映射设计
索引product映射设计
skuId:用于用户点击后查询商品详情
spuId:用户点击商品后查询商品的spu信息,spu还会涉及到一个数据折叠功能,因此设计为keyword类型,后面讲
skuTitle:商品的标题,商品的副标题不进行保存,因为一般用户检索也是检索标题,注意只有商品标题才需要全文检索,因此只将标题设置为text类型并使用ik_smart分词器
skuPrice:做商品价格区间统计聚合使用,为了精度问题设计为keyword
skuImg:设置为
"index": false,让该字段不可被检索,但是可以被作为文档数据查出来,"doc_values": false意思是该字段不需要做聚合操作,冗余存储的字段都可以设置这两个属性来达到节省内存空间的目的【不会被索引和做一些聚合相关的其他操作】saleCount:商品销量用于销量排序
hasStock:是否有库存,用于用户点击仅显示有货按钮检索有库存的商品,存布尔类型,这样的好处是不需要频繁地更新文档数据【文档数据只要修改,ES就会重新索引文档,频繁更新就会极大增加维护索引的开销】,只有在商品没库存的时候才更改ES中的文档数据
hotScore:商品热度评分,用来表征商品的访问量
brandId:品牌id,用于商品按照品牌名进行检索
catalogId:商品分类id,用于商品按照商品分类进行检索
brandName、catalogName、brandImg:这三个字段用于展示对应的品牌图片、名字和商品分类名称,只需要被展示,不需要检索和聚合
attrs:当前商品的属性规格,nested表示attrs是一个数组【这个nested非常重要,不使用nested会出问题,因为spu属性的个数是未知的】,数组的每个元素包含attrId、attrName、attrValue
xxxxxxxxxxPUT product{"mappings": {"properties": {"skuId": {"type": "long"},"spuId": {"type": "keyword"},"skuTitle": {"type": "text","analyzer": "ik_smart"},"skuPrice": {"type": "keyword"},"skuImg": {"type": "keyword","index": false,"doc_values": false},"saleCount": {"type": "long"},"hasStock": {"type": "boolean"},"hotScore": {"type": "long"},"brandId": {"type": "long"},"catelogId": {"type": "long"},"brandName": {"type": "keyword","index": false,"doc_values": false},"brandImg": {"type": "keyword","index": false,"doc_values": false},"catelogName": {"type": "keyword","index": false,"doc_values": false},"attrs": {"type": "nested","properties": {"attrId": {"type": "long"},"attrName": {"type": "keyword","index": false,"doc_values": false},"attrValue": {"type": "keyword"}}}}}}
业务实现
前端点击商品系统spu管理的上架按钮,发送请求
http://localhost:88/api/product/spuinfo/${spuId}/up到后端接口创建ES中product索引文档数据对应的java实体类,注意,因为product模块和search模块都会使用该java实体类,选择将该实体类创建在common模块下,但是实际的微服务开发中,写search模块的哥们根本拿不到common模块的权限,实际上都是product模块中写一个product对应实体类,search模块再写一个相同的实体类
实体类【根据文档映射创建,JavaBean的属性类型与对应数据库实体类的属性类型保持一致,数据库没有的自定义,属性类型用静态内部类创建】
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 对应ES中product索引下的文档映射* @创建日期 2024/05/30* @since 1.0.0*/public class Product {/*** "properties": {* "skuId": {* "type": "long"* },* "spuId": {* "type": "keyword"* },* "skuTitle": {* "type": "text",* "analyzer": "ik_smart"* },* "skuPrice": {* "type": "keyword"* },* "skuImg": {* "type": "keyword",* "index": false,* "doc_values": false* },* "saleCount": {* "type": "long"* },* "hasStock": {* "type": "boolean"* },* "hotScore": {* "type": "long"* },* "brandId": {* "type": "long"* },* "catalogId": {* "type": "long"* },* "brandName": {* "type": "keyword",* "index": false,* "doc_values": false* },* "brandImg": {* "type": "keyword",* "index": false,* "doc_values": false* },* "catalogName": {* "type": "keyword",* "index": false,* "doc_values": false* },* "attrs": {* "type": "nested",* "properties": {* "attrId": {* "type": "long"* },* "attrName": {* "type": "keyword",* "index": false,* "doc_values": false* },* "attrValue": {* "type": "keyword"* }* }* }* }*/private Long skuId;private Long spuId;private String skuTitle;private BigDecimal skuPrice;private String skuImg;private Long saleCount;private Boolean hasStock;private Long hotScore;private Long brandId;private Long catelogId;private String brandName;private String brandImg;private String catelogName;private List<Attr> attrs;/*** @author Earl* @version 1.0.0* @描述 静态内部类也需要添加@Data注解来生成getter和setter* 为了其他第三方工具能对该实体类进行序列化和反序列化,需要添加权限修饰符public* 静态内部类才会和外部的类一起加载* @创建日期 2024/05/30* @since 1.0.0*/public static class Attr{private Long attrId;private String attrName;private String attrValue;}}
后端使用spuId获取spu下的所有skuInfo实体类,对sku信息进行属性对拷,其中属性名不同的有skuPrice【数据库表中为price】,skuImg【skuDefaultImg】,这两个单独拷贝即可;非skuInfo的数据包含hasStock、hotScore、brandName、brandImg、catelogName、Attrs,是否有库存需要给库存模块mall-ware发送请求查询是否有库存,热度评分默认设置为0【但是实际上新品上市热度评分应该要给比较高的权重,实际上热度评分应该是后台一个比较复杂的操作】,单独查询品牌和商品分类的名字并进行拷贝【注意这里还是循环查库,据说后面会优化】,查出当前sku所有的可以被检索的spu规格属性【因为一个sku的所有商品的spu属性都是一样的,所以可以在循环外实现查出来后在循环中进行属性对拷】,先通过spuId从表
pms_arrt_value查出对应的所有spu属性并拿到所有的属性id,拿着所有的属性id从表pms_attr中筛选出字段为search_type为1表示可检索的属性【这个用xml中手写sql实现】,对应SQL语句为resultType为返回值的对应类型
xxxxxxxxxx<select id="selectSearchAttrIds" resultType="java.lang.Long">SELECT attr_id FROM `pms_attr` WHERE attr_id IN<foreach collection="attrIds" item="id" separator="," open="(" close=")">#{id}</foreach>AND search_type=1</select>将查出的满足搜索条件的属性id转换成一个Set集合
new HashSet<>(List集合)可以直接将List集合转换成set集合,对pms_arrt_value查出的数据进行过滤,检查对应的元素的属性id是否在set集合中,在则过滤出来作为商品的规格属性封装到ES文档数据中,属性表的字段名和ES文档类中的Attr的属性名都是相同的,可以直接属性对拷远程查询库存系统是否还含有库存的业务实现,,远程调用也是传递skuId来调库存模块获取每种商品是否含义库存,如果循环调用,性能非常慢,需要一次调用,获取所有skuId的库存状态;在ware模块中写一个通过skuId集合查询表
wms_ware_sku表对应sku是否含有库存的接口,用实体类传递响应内容,用map多客户端协调不容易知道响应内容,用Vo不需要浏览代码就知道响应内容;用wms_ware_sku表中商品总库存数量减去锁定库存的数量是否大于0来判断商品是否有货【锁定的库存是用户已经下单但是还没有支付完】,SUM()计算两个字段的加减运算,返回数据可以使用泛型来标记响应数据的类型,这样数据可以直接自动转换到存入类型,而不需要自己拿到数据再进行强转,当然,当前模块还是需要一份对应的Vo或者To类,renren项目的响应R是没有涉及泛型的,远程调用查询网络可能存在波动,用try,catch来应对万一发生的网络波动,失败就打印日志,不管失败还是成功都要继续执行上架的功能【没有库存了还是上架并设置仍然有库存】将数据使用
mall-search模块发送给ES服务器进行保存,代码接口/search/save/up/product,批量操作进行保存,全部保存成功即成功,没有全部成功返回商品上架异常错误码,但是已经上传的商品仍然上架此时还存在问题,第一商品上架重复调用即上架服务接口幂等性的问题【search模块中商品上架失败要考虑是否需要重试,多次调用是否以及如何保证幂等性问题】
主要代码
xxxxxxxxxx/*** @param spuId* @描述 使用spuId实现商品上架功能* 1. 查询出对应ES的product索引文档映射对应实体类com.earl.common.to.es.Product的全部数据* @author Earl* @version 1.0.0* @创建日期 2024/05/31* @since 1.0.0*/public void upProduct(Long spuId) {//查询spuId下的所有skuInfo信息List<SkuInfoEntity> skuInfoEntities = skuInfoService.list(new QueryWrapper<SkuInfoEntity>().eq("spu_id", spuId));//获取spuId下的所有skuIdList<Long> skuIds = skuInfoEntities.stream().map(skuInfoEntity -> skuInfoEntity.getSkuId()).collect(Collectors.toList());//1. 远程调用mall-stock服务查询skuId列表对应的商品是否还有库存//注意TypeReference的构造器修饰符是protected,只能通过内部类的方式来创建对象Map<Long, Boolean> stockStatus = null;try{List<SkuStockExistTo> skuStockExistTos = stockFeignClient.isStockExist(skuIds).getData(new TypeReference<List<SkuStockExistTo>>() {});//将该集合skuStockExistTos转成Map准备属性对拷stockStatus = skuStockExistTos.stream().collect(Collectors.toMap(SkuStockExistTo::getSkuId, SkuStockExistTo::getIsExist));}catch (Exception e){log.error("远程调用库存服务超时,原因:{}",e);}//3. 根据品牌Id和catelogId查询出对应的品牌名、商品分类名以及品牌图片//获取品牌名和品牌图片List<Long> brandIds = skuInfoEntities.stream().map(skuInfoEntity -> skuInfoEntity.getBrandId()).distinct().collect(Collectors.toList());Map<Long, BrandEntity> brands = brandService.list(new QueryWrapper<BrandEntity>().in("brand_id", brandIds)).stream().collect(Collectors.toMap(BrandEntity::getBrandId, brandEntity -> brandEntity));//获取商品分类名List<Long> catelogIds = skuInfoEntities.stream().map(skuInfoEntity -> skuInfoEntity.getCatelogId()).distinct().collect(Collectors.toList());Map<Long, String> cateLogNames = categoryService.list(new QueryWrapper<CategoryEntity>().in("cat_id", catelogIds)).stream().collect(Collectors.toMap(CategoryEntity::getCatId, CategoryEntity::getName));//4. 获取所有可被搜索的spu规格属性//查询spuId下所有的属性idList<ProductAttrValueEntity> attrValueEntities = productAttrValueService.list(new QueryWrapper<ProductAttrValueEntity>().eq("spu_id", spuId));List<Long> attrIds = attrValueEntities.stream().map(attrValueEntity -> attrValueEntity.getAttrId()).collect(Collectors.toList());//获取可检索的属性id列表Set<Long> searchableAttrIds = attrService.list(new QueryWrapper<AttrEntity>().eq("search_type", 1).in("attr_id", attrIds)).stream().map(attrEntity -> attrEntity.getAttrId()).collect(Collectors.toSet());//组装为Attr属性的集合List<Product.Attr> attrs = attrValueEntities.stream().filter(attrValueEntity -> searchableAttrIds.contains(attrValueEntity.getAttrId())).map(attrValueEntity -> {Product.Attr attr = new Product.Attr();BeanUtils.copyProperties(attrValueEntity, attr);return attr;}).collect(Collectors.toList());//5. 准备已经拷贝skuId、spuId、skuTitle、brandId、catelogId的传输至ES的product文档记录列表和skuInfo列表对拷,并拷贝处理此前处理的所有数据Map<Long, Boolean> finalStockStatus = stockStatus;List<Product> products = skuInfoEntities.stream().map(skuInfoEntity -> {Product product = new Product();BeanUtils.copyProperties(skuInfoEntity, product);//将其中的sku_default_img和price字段拷贝至product文档记录列表product.setSkuImg(skuInfoEntity.getSkuDefaultImg());product.setSkuPrice(skuInfoEntity.getPrice());//2. 设置商品的热度评分,默认设置为0,实际上是热度评分是一个很复杂的功能product.setHotScore(0L);//将库存状态拷贝至文档数据// 这里为什么报错:Lambda表达式可能在另一个线程中执行,如果这个局部变量在外部或者Lambda内部或者同时发生修改,那么可能出现线程安全问题。// 所以需要设置局部变量为final或者为effectively final的,来防止发生修改操作product.setHasStock(finalStockStatus == null? true : finalStockStatus.get(product.getSkuId()));//将品牌和分类名进行拷贝BrandEntity brand = brands.get(product.getBrandId());product.setBrandName(brand.getName());product.setBrandImg(brand.getLogo());product.setCatelogName(cateLogNames.get(product.getCatelogId()));//将可检索规格属性列表拷贝到文档product.setAttrs(attrs);return product;}).collect(Collectors.toList());//6. 将文档数据products远程调用mall-search服务上传至ES服务器R response = searchFeignClient.upProduct(products);//上架成功修改数据库表pms_spu_info中的spu的字段publish_status为1,表示商品上架成功if(response.getCode()==0){//远程调用成功且商品全部成功上架,将上架状态改为1SpuInfoEntity spuInfoEntity = new SpuInfoEntity();spuInfoEntity.setId(spuId);spuInfoEntity.setPublishStatus(ProductConstant.UpStatusEnum.SPU_UP.getCode());baseMapper.updateById(spuInfoEntity);}else{//远程调用失败,要考虑//TODO 重复调用即商品上架接口的幂等性问题以及商品上架失败重试机制的问题}}远程调用商品上架服务,调用失败会有重试机制,服务调用用的是Feign的重试机制,
SynchronousMethodHandler中调用Retryer的continueOrPropagate重试代码如下当第一次尝试
this.executeAndDecode(template)发生了异常,异常被捕获并调用retryer.continueOrPropagate(e)来进行重试retryer.continueOrPropagate(e)如果重试的最大次数超过maxAttempts【默认值是5】,则抛异常e被invoke方法捕获如果没超次数,
retryer.continueOrPropagate(e)执行后,由于while(true)死循环,该方法还会继续执行,直到抛异常或者执行成功才会从该循环中跳出
【
SynchronousMethodHandler的invoke代码】xxxxxxxxxxpublic Object invoke(Object[] argv) throws Throwable {RequestTemplate template = this.buildTemplateFromArgs.create(argv);Retryer retryer = this.retryer.clone();while(true) {try {return this.executeAndDecode(template);} catch (RetryableException var8) {RetryableException e = var8;try {retryer.continueOrPropagate(e);} catch (RetryableException var7) {Throwable cause = var7.getCause();if (this.propagationPolicy == ExceptionPropagationPolicy.UNWRAP && cause != null) {throw cause;}throw var7;}if (this.logLevel != Level.NONE) {this.logger.logRetry(this.metadata.configKey(), this.logLevel);}}}}【Retryer部分代码】
xxxxxxxxxxpublic void continueOrPropagate(RetryableException e) {if (this.attempt++ >= this.maxAttempts) {throw e;} else {long interval;if (e.retryAfter() != null) {interval = e.retryAfter().getTime() - this.currentTimeMillis();if (interval > this.maxPeriod) {interval = this.maxPeriod;}if (interval < 0L) {return;}} else {interval = this.nextMaxInterval();}try {Thread.sleep(interval);} catch (InterruptedException var5) {Thread.currentThread().interrupt();throw e;}this.sleptForMillis += interval;}}【
SynchronousMethodHandler的invoke代码】xxxxxxxxxxpublic Object invoke(Object[] argv) throws Throwable {RequestTemplate template = this.buildTemplateFromArgs.create(argv);Retryer retryer = this.retryer.clone();while(true) {try {return this.executeAndDecode(template);} catch (RetryableException var8) {RetryableException e = var8;try {retryer.continueOrPropagate(e);} catch (RetryableException var7) {Throwable cause = var7.getCause();if (this.propagationPolicy == ExceptionPropagationPolicy.UNWRAP && cause != null) {throw cause;}throw var7;}if (this.logLevel != Level.NONE) {this.logger.logRetry(this.metadata.configKey(), this.logLevel);}}}}
nested数据类型
在ES中将nested称为嵌入式的,官方文档介绍,数组类型的请求体中的json对象会被扁平化处理,扁平化处理的概念看下列介绍
使用nested数据类型的数据不论是检索匹配还是聚合分析都要使用对应nested方式的查询和聚合分析,否则使用一般的查询和聚合方式一条数据也查不出来
数组扁平化处理
请求体提交数据
xxxxxxxxxxPUT my_index/_doc/1{"group": "fans","user": [{"first": "John","last": "Smith"},{"first": "Alice","last": "White"}]}将在ES中被处理转换后的文档
即将数组每个对象的属性名和数组名结合起来,将对象的每一个属性作为一个数组
xxxxxxxxxx{"group": "fans","user.first": ["alice","john"],"user.last": ["smith","white"]}这种方式存在的问题
因为数组被扁平化处理了,在用户层面理解的检索条件如
xxxxxxxxxxGET my_index/_search{"query": {"bool": {"must": [{"match": {"user.first": "Alice"}},{"match": {"user.last": "Smith"}}]}}}检索结果
xxxxxxxxxx{"took" : 12,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.5753642,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 0.5753642,"_source" : {"group" : "fans","user" : [{"first" : "John","last" : "Smith"},{"first" : "Alice","last" : "White"}]}}]}}数组的默认映射是将
user.first作为一个带keyword的text,并不是nestedxxxxxxxxxx{"my_index" : {"mappings" : {"properties" : {"group" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"user" : {"properties" : {"first" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"last" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}}}}用户需要找到同时满足
"user.first": "Alice"且"user.last": "Smith"的数据,从存储的数据上来看并没有满足这样要求的数据,但是实际运行还是会得到全部的文档数据,因为数组被扁平化处理了,ES只会去检索数组user.first中是否含有Alice,同时去检查user.last数组中去检查是否含有Smith,发现该文档两个数组都满足检索条件,就会返回该文档数据,实际上这两个条件并不同时满足在同一个对象的要求,即数组被处理的无法处理同一个对象的属性之间的联系,这样会发生检索错误的问题,需要使用nested数据类型【注意这种问题一般发生在数组元素是对象的情况下,数组元素是单个值不会发生这样的情况】
使用nested类型来定义索引的映射关系
此时再向该索引下索引对应的文档数据并使用相同的条件检索文档,不会再发生检索出错误数据的问题
xxxxxxxxxxPUT my_index{"mappings": {"properties": {"user": {"type": "nested"}}}}检索结果
xxxxxxxxxx{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]}}此时的映射关系为
只是给user即数组元素对象增加了一个
nested类型,增加以后的效果是不会发生扁平化处理产生的不能区分同一个对象属性联系的问题,但是没有讲明具体的区分原理,通过WEB APIGET my_index/_mapping可以查看哪些属性被设置为哪种类型
xxxxxxxxxxGET my_index/_mapping{"my_index" : {"mappings" : {"properties" : {"group" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"user" : {"type" : "nested","properties" : {"first" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"last" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}}}}因此数组元素为多属性对象时一定要在索引映射中声明该对象是一个
nested数据类型
nested数据查询
nested数据类型的查询
如果一个属性被声明为
nested类型,通过该属性查询文档必须使用nested对应的查询语法进行查询,否则查询不到文档数据
1️⃣[nested类型数据使用原始查询方式查不到数据示例]
xxxxxxxxxxGET product/_search{"query": {"bool": {"filter": {"term": {"attrs.attrId": "11"}}}}}[响应内容]
通过普通方式查询
nested类型的数据没有查到一条记录
xxxxxxxxxx{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]}}2️⃣[nested类型数据正确查询方式]
nested语句中的path属性指定文档中的匹配属性名,就是设置为nested类型的属性attrs,因为attrs中是一个未知元素个数的数组,所以attrs属性被设置为nested类型,数组中的每一个元素都可能是一个
json对象,每个json对象都有确定个数的多个属性名和属性值,这些要匹配的属性名和属性值在query语句中指定,注意属性名需要写完整的属性名即attrs.attrId,不要忽略前缀写attrId注意
term和terms都是匹配同一个字段,term是匹配属性值为单一值的记录,terms是匹配属性值为多个可能值的所有记录的并集注意使用了正确的
nested查询语句的同时仍然不能使用一般语句来匹配nested类型的数据,同样不会查询到一条记录
xxxxxxxxxxGET product/_search{"query": {"bool": {"filter": {"nested": {"path": "attrs","query": {"bool": {"must": [{"term": {"attrs.attrId": "11"}},{"terms": {"attrs.attrValue": ["海思芯片","以官网信息为准"]}}]}}}}}}}[响应内容]
xxxxxxxxxx{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 8,"relation" : "eq"},"max_score" : 0.0,"hits" : [{"_index" : "product","_type" : "_doc","_id" : "5","_score" : 0.0,"_source" : {"attrs" : [{"attrId" : 3,"attrName" : "入网型号","attrValue" : "LIO-AL00;是;否"},{"attrId" : 11,"attrName" : "CPU品牌","attrValue" : "海思芯片"}],"brandId" : 4,"brandImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName" : "华为","catelogId" : 225,"catelogName" : "手机","hasStock" : false,"hotScore" : 0,"saleCount" : 0,"skuId" : 5,"skuImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice" : 5699.0,"skuTitle" : "华为 HUAWEI Mate60 Pro 星河银 128G 旗舰新品手机","spuId" : 5}},{"_index" : "product","_type" : "_doc","_id" : "6","_score" : 0.0,"_source" : {"attrs" : [{"attrId" : 3,"attrName" : "入网型号","attrValue" : "LIO-AL00;是;否"},{"attrId" : 11,"attrName" : "CPU品牌","attrValue" : "海思芯片"}],"brandId" : 4,"brandImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName" : "华为","catelogId" : 225,"catelogName" : "手机","hasStock" : true,"hotScore" : 0,"saleCount" : 0,"skuId" : 6,"skuImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice" : 6299.0,"skuTitle" : "华为 HUAWEI Mate60 Pro 星河银 256G 旗舰新品手机","spuId" : 5}},,{"_index" : "product","_type" : "_doc","_id" : "12","_score" : 0.0,"_source" : {"attrs" : [{"attrId" : 3,"attrName" : "入网型号","attrValue" : "LIO-AL00;是;否"},{"attrId" : 11,"attrName" : "CPU品牌","attrValue" : "海思芯片"}],"brandId" : 4,"brandImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/03/ca1e4c86-a0f0-4a46-8fa9-db8f92bbc0a1_huawei.png","brandName" : "华为","catelogId" : 225,"catelogName" : "手机","hasStock" : false,"hotScore" : 0,"saleCount" : 0,"skuId" : 12,"skuImg" : "https://demo2-mall.oss-cn-chengdu.aliyuncs.com/2024/03/26//e87743d5-526d-467b-855d-6213f64b0965_0d40c24b264aa511.jpg","skuPrice" : 6299.0,"skuTitle" : "华为 HUAWEI Mate60 Pro 罗兰紫 256G 旗舰新品手机","spuId" : 5}}]}}
nested数据聚合
聚合分析所有检索到的记录的nested类型的数据
attrsnested类型的数据进行聚合除了要在一般的聚合分析外面多套一层聚合分析并且用nested对象的path属性指明要被聚合分析的nested类型的字段,如下例所示
[语法格式]
第一个comments是聚合的自定义名字,age_group也是聚合的自定义名字,blogposts也是自定义聚合的名字
xxxxxxxxxxGET /my_index/blogpost/_search{"size" : 0,"aggs": {"comments": {"nested": {"path": "comments"},"aggs": {"age_group": {"histogram": {"field": "comments.age","interval": 10},"aggs": {"blogposts": {"reverse_nested": {},"aggs": {"tags": {"terms": {"field": "tags"}}}}}}}}}}1️⃣[对nested类型数据聚合查询]
xxxxxxxxxxGET mall_product/_search{"query": {"match_all": {}},"aggs": {"brand_agg": {},"catelog_agg": {},"attrs_agg": {"nested": {"path": "attrs"},"aggs": {"attrs_id_agg": {"terms": {"field": "attrs.attrId","size": 10},"aggs": {"attr_name_agg": {"terms": {"field": "attrs.attrName","size": 10}},"attr_value_agg": {"terms": {"field": "attrs.attrValue","size": 10}}}}}}}}[响应结果]
xxxxxxxxxx"aggregations" : {"attrs_agg" : {"doc_count" : 24,"attrs_id_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 3,"doc_count" : 12,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "入网型号","doc_count" : 12}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "LIO-AL00;是;否","doc_count" : 8},{"key" : "LIO-AL00","doc_count" : 4}]}},{"key" : 11,"doc_count" : 12,"attr_name_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "CPU品牌","doc_count" : 12}]},"attr_value_agg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "海思芯片","doc_count" : 8},{"key" : "Apple芯片","doc_count" : 4}]}}]}},"catelog_agg" : {},"brand_agg" : {}}
附录
画图软件:Balsamiq Mockups
画一下框架图很好用,看一些视频介绍还可以拿来设计网页,据说是产品原型设计软件
ELK是ELasticsearch、LogStash、Kibana三个软件的首字母
Elasticsearch是全文检索工具
Kibana是页面管理工具,可以通过Kibana的管理界面操作Elasticsearch
LogStash是日志收集工具,通过该工具可以实现日志内容收集和格式转换
Get请求也能携带请求体json
讲的太垃圾,根本没说如何设置routing为自定义路由参数,如何根据自定义的routing参数分配数据到指定分片上,并由此根据数据分片特点以特定的自定义routing参数让一次查询请求集中在一个分片上来提升查询效率
浏览器支持的请求方式不多,只有get、put、等少数几种方式,可以使用postman发起更多方式的请求,postman可以发送任何类型的Http请求,不仅可以提交表单数据,还可以提交任意类型的请求体